C++内存管理
C++的内存分配
- malloc(), free() : C函数,不可重载
- new, delete: C++表达式,不可重载
- ::operator new(), ::operator delete(): C++函数(全局),可重载
- allocator<\T>::allocate(), allocator<\T>::deallocate(): C++标准库,可自由设计
直接使用标准库的内存分配器(一般不使用):
int* p = allocate<int>().allocate(5);
allocate<int>().deallocate(p, 5);new与delete的实质
new表达式的解析:
Complex* pc = new Complex(1, 2);
// 编译为
void* mem = operator new(sizeof(Complex)); // 注意operator new是可以重载的,默认是全局的函数
pc = static_cast<Complex*>(mem);
pc->Complex::Complex(1, 2); // 调用Complex的构造函数,注意只有编译器可以这样调用构造函数,代码不能这么写
// 其中的operator new源码
// 保证不抛出异常
void* operator new(size_t size, const std::nothrow_t&)
_THROW0()
{
void* p;
while(p == malloc(size))
{
_TRY_BRGIN
if(_callnewh(size) == 0) break;
_CACHE(sth::bad_alloc) return (0);
_CACHE_END
}
}delete表达式的解析:
...
delete pc;
// 编译为
pc->~Complex(); //析构函数是可以直接调用的
operator delete(pc);
// operator delete源码
void operator delete(void* p) _THROW0()
{
free(p);
}所以new,delete底层是使用的operator new()和operator delete()。
内容丢失(关于定位new,array new)
重载operator函数
重载operator函数是进行内存管理的重要手段之一。new表达式是不可以重载的,但是它调用了operator new来间接调用malloc来分配内存,我们可以重载operator new来修改对象的内存分配行为。
重载operator new函数是可以自定义参数,但是第一个参数必须是一个size_t。当使用new表达式时,可以传入这些参数,一般第一个参数会自动计算类的大小。
Foo* p = new(300, xxx) Foo;同理operator delete也可以如此,但即使operator delete没有一一对应operator new,编译器也只会警告,不会报错。
内存管理的一个方法是减少malloc的调用次数(增加速度),并且减少cookie的内存占用(减少大小)。
一个示例(来自Effective C++):
class Airpalne{
private:
// 这里面是Airpalne的数据,把它包装成一个结构体
struct AirplaneRep{
unsigned long miles;
char type;
};
private:
// 这块内存使用时他是AirplaneRep(就是Airpalne的数据),未使用时是 Airpalne*
// 这种设计方式叫做embedded pointer
union {
AirplaneRep rep;
Airpalne* next;
}
public:
...
static void* operator new(size_t size);
static void operator new(void* deadObject, size_t size);
private:
static const int BLOCK_SZIE;
static Airpalne* headOfFreeList;
};
Airpalne* Airpalne::headOfFreeList;
const int Airpalne::BLOCK_SZIE = 512;
// 重载的operator new
void* Airpalne::operator new(size_t size)
{
// 检测size大小,当有继承时大小可能有误
if (size != sizeof(Airplane))
return ::operator new(size)
Airplane* p = headOfFreeList;
if (p) // headOfFreeList有效,分配后移动到下一个节点
headOfFreeList = p->next
else{
// free list已空,再申请一大块内存
Airplane* newBlock = static_cast<Airplane*>(::operator new(BLOCK_SZIE * sizeof(Airplane)))
// 将它串成free list
// 跳过第一个(i = 0),它是本次分配的结果
for (int i = 1; i < BLOCK_SZIE - 1; ++i)
newBlock[i].next = &newBlock[i + 1];
newBlock[BLOCK_SZIE - 1].next = 0; // 这里最新的C++应该用nullptr
p = newBlock;
headOfFreeList = newBlock[i];
}
return p;
}
void Airpalne::operator delete(void* deadObject, size_t size)
{
if(deadObject == 0) return;
if(size != sizeof(Airpalne)) {
::operator delete(deadObject);
return;
}
// 将释放的内存插入到headOfFreeList之前
Airplane* carcass = static_cast<Airplane*>(deadObject);
carcass->next = headOfFreeList;
headOfFreeList = carcass;
}查看operator delete函数,我们可以发现释放内存时并没有将内存还给操作系统,这会导致headOfFreeList的尺寸越来越大,这是这种重载方法的一点缺陷。
static allocator
针对上面的重载方式进行改进,我们不想为每一个需要内存管理的类都写一遍重载方法,可以将其抽取出来作为单独的类,这个类就叫做allocator。
class allocator
{
private:
// obj结构体至少可以储存一个指针(一般为8字节)
struct obj{
struct obj* next; // enbedded pointer
};
public:
void* allocate(size_t);
void deallocate(void*, size_t);
private:
obj* freeStore = nullptr;
const int CHUNK = 5;
};
// 实现方案与上面的相同
void* allocator::allocate(size_t size)
{
obj* p;
if (!freeStore)
{
size_t chunk = CHUNK * size;
p = (obj*)malloc(chunk);
freeStore = p;
// 这里由于没有获得真正对象的指针类型,所以偏移时每次偏移size,需要转换为char类型计算。之前的Airplane已经知道了对象的指针类型,所以可以直接++(使用[]运算符)。
for(int i = 0; i < CHUNK - 1; ++i)
{
p->next = (obj*)((char*)p + size);
p = p->next;
}
p->next = nullptr;
}
p = freeStore;
freeStore = freeStore->next;
return p;
}
void allocator::deallocate(void* p, size_t size)
{
...
}有了这个allocator之后,如果有一个类要使用内存管理,可以直接集成这个类:
class Foo
{
public:
...
static allocator myAlloc;
public:
static void* operator new(size_t size)
{
return myAlloc.allocate(size);
}
static void operator delete(void* p, size_t size)
{
return myAlloc.deallocate(p, size);
}
...
};
allocator Foo::myAlloc;这种将allocator作为类的静态成员的方式称为static allocator。这个设计的精妙之处在于,allocator只要保存一个指针,他就可以将这个指针指向任何C++的对象,指针指向内存的大小取决于类的大小,即传入的size,调用完allocate后(在operator new中),会自动调用类的构造函数来在size大小的内存上创建一个对象。
在这里,就已经开始有内存分配器这个概念了。
macro for static allocator
针对static allocator进一步优化,我们发现,使用static allocator的代码基本是相同的,所以我们可以使用一个宏定义来简化代码。
#define DECLARE_POOL_ALLOC()\
public:\
static void* operator new(size_t size)
{\
return myAlloc.allocate(size);\
}\
...
protect:\
static allocator myAlloc;
#define IMPLEMENT_POOL_ALLOC(class_name)\
allocator class_name::myAlloc;这样的话,一个类中集成分配器就可以写成:
class Foo
{
DECLARE_POOL_ALLOC()
private:
...
};
IMPLEMENT_POOL_ALLOC(Foo)比原来的代码简化了很多。这种优化并不是技术上的优化,只是简化代码的编写。
new handler
当operator new无法分配内存时,会抛出异常 std::bad_alloc exception,但是在抛出异常之前,C++会执行一个函数。
typedef void (*new_handler)(); //由自己实现,处理分配内存异常的情形
new_handler set_new_handler(new_handler p) throw(); // 设置new handler一个new_handler示例:
void noMoreMemory()
{
cerr<<"Out if memory";
abort();
}
void main()
{
set_new_handler(noMoreMemory);
...
}这样,在operator new无法分配内存时,就会打印错误信息并中断程序。
default, delete
一般来说,只有类的构造函数,拷贝构造函数,赋值运算符,析构函数会使用这两个关键字(构造函数没有delete)。其实这两个关键字也可以用于operator new/new[]和operator delete/delete[],其中operator new和operator delete不能使用default,如果使用了delete,会导致new与delete表达式无法使用。
std::allocator
各种标准库的分配器
在C++中,一次分配内存时,会产生额外8字节的cookie和可能的32字节的debug信息(因不同的编译器而异)。对于一些占用内存小,使用次数多的类来说是一个比较大的浪费,所以需要使用内存管理来优化。
VC6标准库的分配器实现如下:
template<class _Ty>
class allocator{
public:
typedef _Ty _FARQ *pointer;
...
pointer allocate(size_type _N, const void*)
{ return (_Allocate((difference_type) _N, (pointer)0));}
...
}
//其中_Allocate定义
template<class _Ty> inline
_Ty _FARQ *_Allocate(_PDFT _N, _Ty _FARQ)
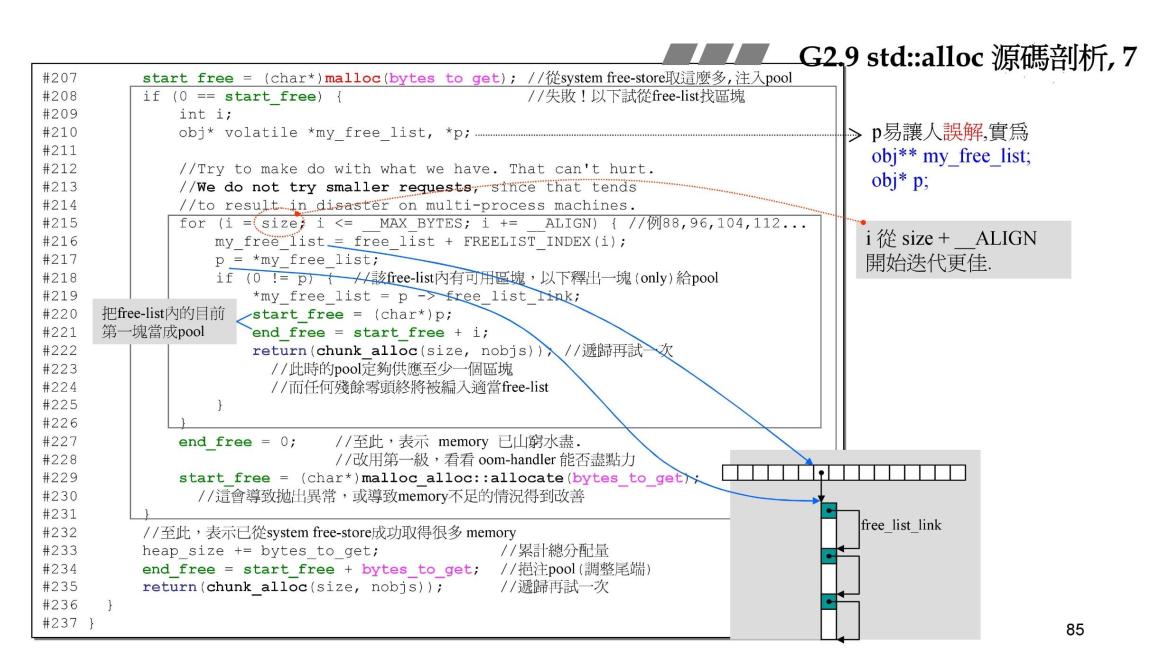
{
if (_N < 0) _N = 0;
return ((_Ty _FARQ) operator new((_SIZT)_N * sizeof(_Ty)))
}
//使用
int *p = allocator<int>().allocate(512, (int*)0);
...
allocator<int>().deallocate(p, 512)可以看出,VC6中的allocator并没有做任何内存管理,直接包装了一下operator new。
同样,BC5中的标准分配器也是如此。
G2.9的标准分配器实现如下:

看起来也是没有做任何内存管理,但是G2.9中提示不要使用这个标准分配器,它有一个自己的分配器,s这个分配器并未使用到任何一个容器。
而G2.9中使用的真正分配器叫做std::alloc,到了G4.9,又换成了__pool_alloc,它们的实现是相似的,都做了很好的内存管理。
G2.9的std::alloc
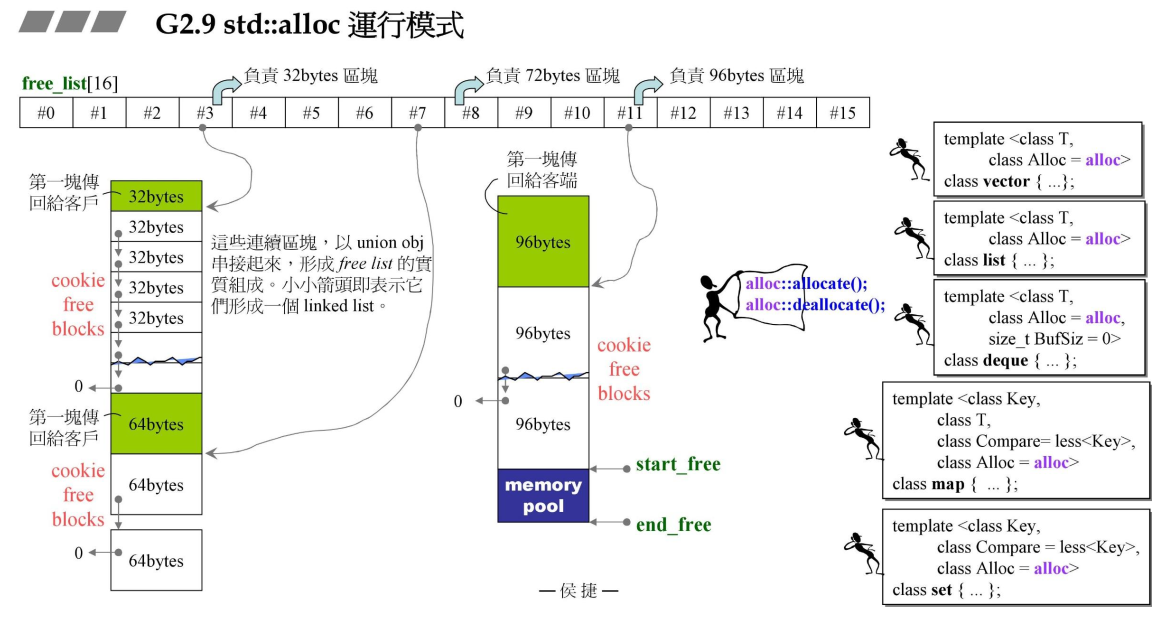
分配器中维护了16个链表,每个链表负责不同大小的内存分配,第一个是8字节,第二个是16字节,依次类推。当进行内存分配时,会自动将内存调整到8的倍数。
在上图中,如果需要分配32个字节,会由#3这个链表拿出32个字节的内存,如果没有,#3链表会使用malloc申请20 * 2 * 32 + RoundUp(累计申请量 >> 4)字节的内存,前20 * 32用于#3链表的使用,取余用于各个链表的备用(pool),下一次进行内存分配时,不论分配的内存大小是多少,都会先查看pool中的内存是否符合要求(可不可以切分成最多20*内存大小的链表并且至少满足此次的内存分配),不够再去使用malloc分配新的内存。同理释放内存时,会根据释放内存大小来把这块内存放到对应的链表上。
如果pool中的内存不满足一次内存分配的大小,就会去申请新的内存,此时会产生内存碎片。比如pool中还剩余80字节大小,现在要去分配108字节的内存,80字节不满足分配条件,std::alloc会去申请新的内存,这80个字节就成为了内存碎片,此时std::alloc会把这个内存碎片插入到对应的链表中,比如#9链表负责80字节的内存分配,这80字节就插入到#9链表后,以此来减少内存的分配。
当申请的内存大于16个链表所负责的内存内存大小时,比如分配256个字节时,即使#15负责的内存也没有这么大,此时就会使用malloc来分配内存。
每一个链表都使用了embedded pointers的设计方式和上面重载operator的示例相同。embedded pointers中有一个要求,分配内存的对象必须大于4个字节(32位系统),毕竟要借用这个对象的内存来储存一个指针。
系统内存消耗完毕时,std::alloc开始回收资源,它会将第一个大于此次内存申请的链表进行回收,把它的内存回填到pool中。比如内存已经消耗完了,现在在申请72字节的内存(负责72字节内存分配的链表已经没有节点了),std::alloc会先查看#7链表(负责80字节)中是否由空置的内存节点,如果有则从#7链表中回收80个字节(一个节点)到pool中,如果没有则继续寻找下一个链表。同时,将80字节回收到pool中后,进行72字节的内存分配,会留下8字节的内存碎片,这个内存碎片也会按照上面的流程回收。
源码
第一级分配器:
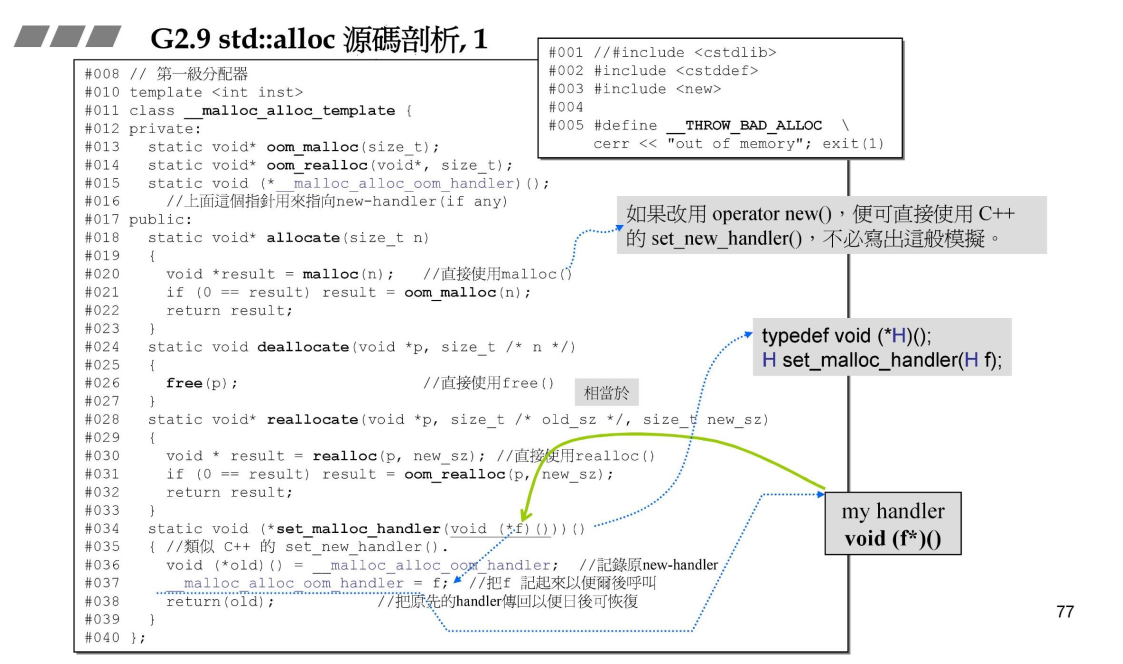
直接使用malloc申请内存。
第二级分配器

__default_alloc_template分析:
3个枚举定义:
__ALING = 8; // 以8字节对齐
__MAX_BYTES = 128; // 最多分配128字节
__NFREELISTS = __MAX_BYTES / __ALING; // 16个链表ROUND_UP函数用于将bytes调整至8的倍数。
embedded pointer:
union obj {
unoin obj* free_list_link; //next指针
}FREELIST_INDEX 计算bytes大小的内存对应几号链表。
free_list就是内存链表的数组,它包含了16个链表。
refill函数用于充值内存,向链表中加入内存节点。
chunk_alloc函数一次分配一大块内存。
其余的变量已经注释。
两个核心的函数 allocate 和 deallocate:
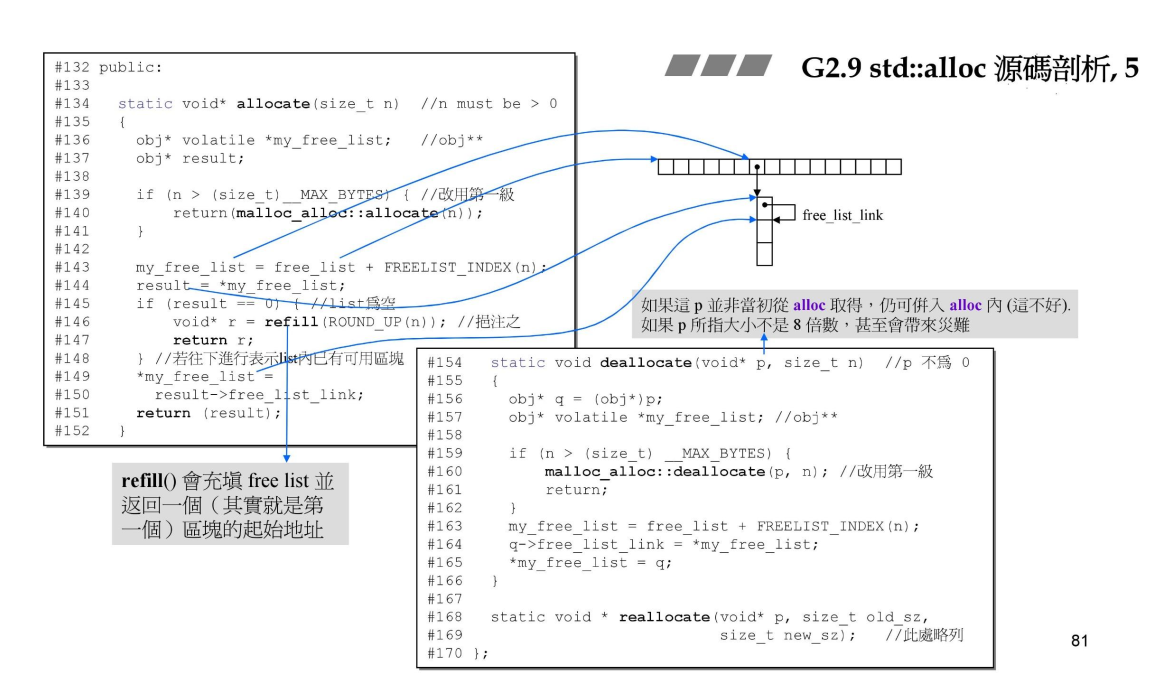
可以发现deallocate中并没有free内存,也就是说,释放内存时并没有把内存还给操作系统。
refill函数:

chunk_alloc函数:
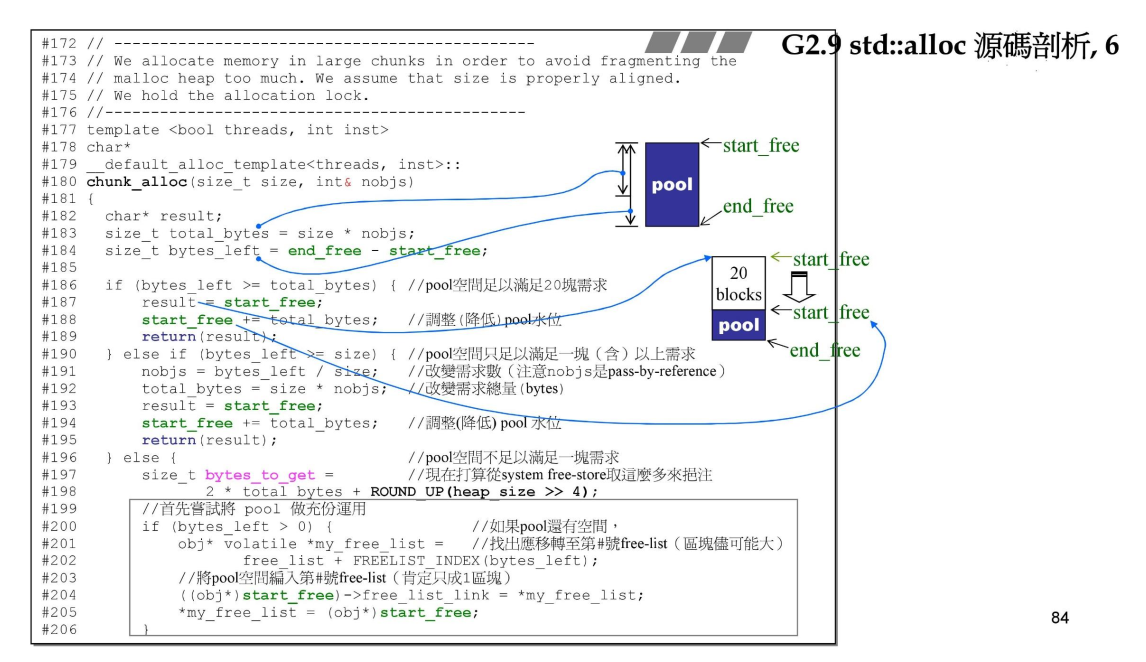
std::alloc的定义:
template <bool threads, int inst>
__default_alloc_template<threads, inst>::obj* volatile;
__default_alloc_template<threads, inst>::free_list[__NFREELISTS] = {0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, }; //__NFREELISTS == 16
typedef __default_alloc_template<false, 0> alloc;std::alloc使用示例:
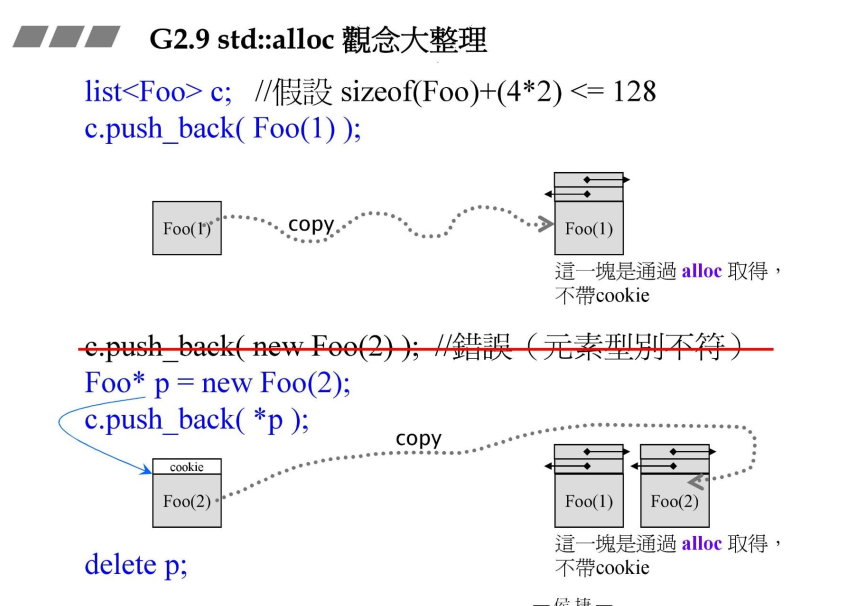
上面的示例中,直接push_back(Foo(1))时std::list会使用std::alloc分配内存,然后把Foo(1)copy到list的内存中,而使用new先在堆上创建内存后,再push_back到list中时,list同样使用std::alloc分配内存,然后把该对象不带cookie的部分copy到自己的内存中。
malloc和free
VC内存分配

上图为C++程序运行调用栈
_heap_alloc_base函数分配程序运行所需的内存,从函数中可以看到,当分配的内存小于1016字节时,使用的是__sbh_alloc_block来分配内存,否则使用HeapAlloc来分配内存。
而在VC10中,内存分配的函数为:

可以看到不论分配的内存大小为多少,都是用HeapAlloc来分配内存。
__heap_init()
观察上面的调用栈,这两个函数是程序运行的第一步,可理解为初始化,他的源码为:
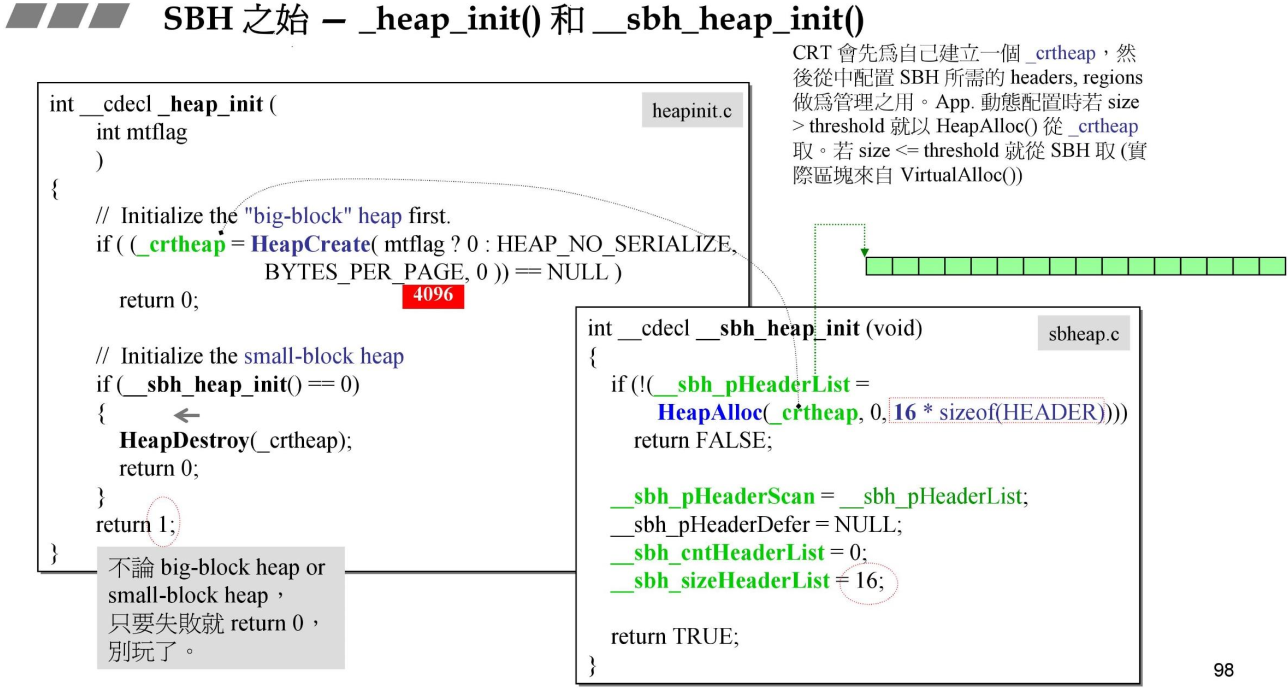
申请了16个HEADER的内存。HEADER的定义:

ioinit()
初始化io相关内存,
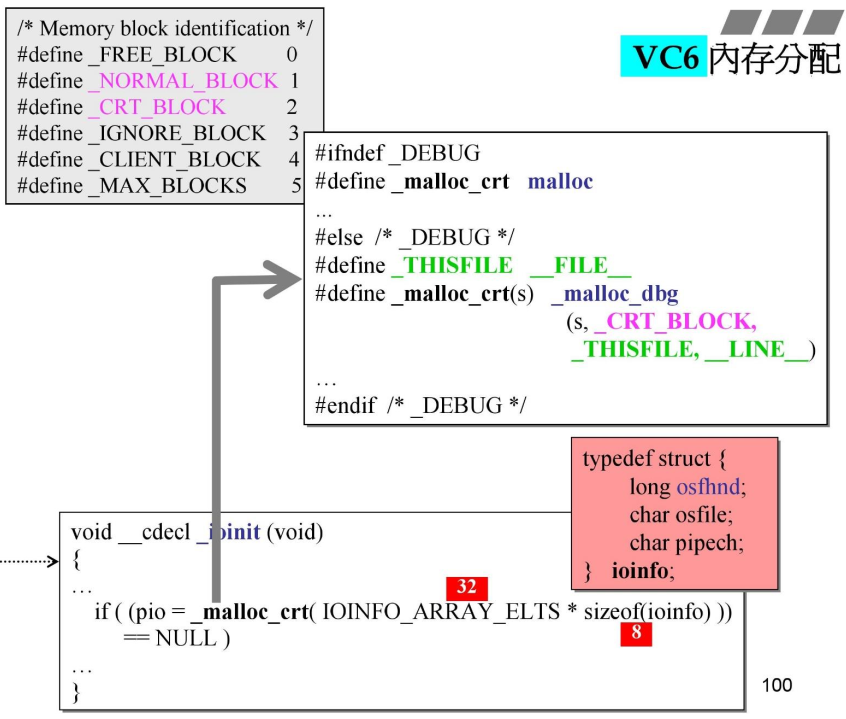
在ioinit中,使用了_malloc_crt函数来分配内存,再dbg模式下,该函数的真正定义为_malloc_dbg。
它一共分配了32 * 8 = 256个字节的内存。
而在_malloc_dbg中,调用了_heap_alloc_dbg函数,其中有一段代码:

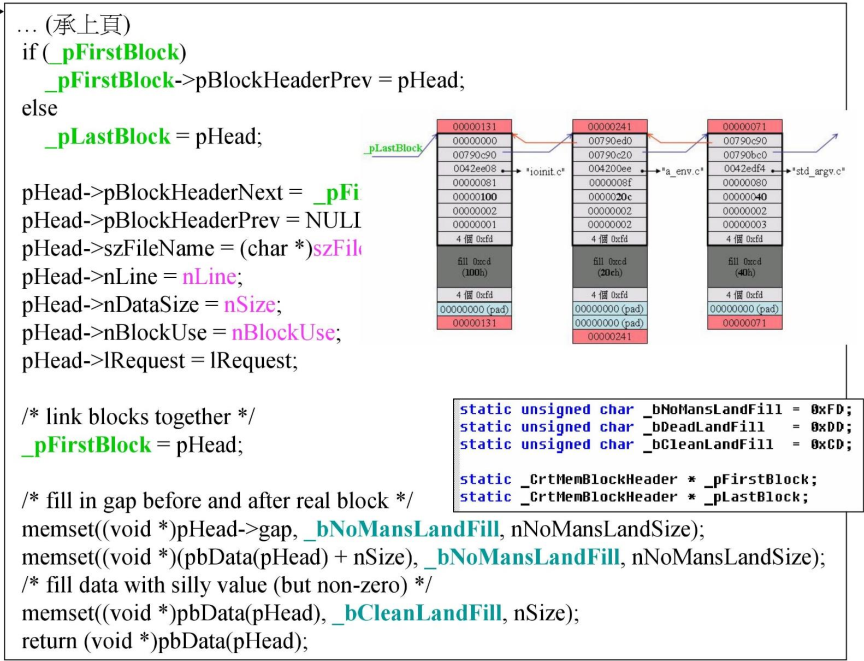
其中nSize为256字节(上面_malloc_crt的参数),nNoMansLandSize = 4, _CrtMemBlockHeader是debug模式下附加的内存,共32字节(cookie)。
其中涉及了两个指针 _pFirstBlock和_pLastBlock。
最后使用了memset函数填充了内存的值,0xFD, 0xDD…。调试器在不同的内存中填充不同的值,这样就可以追踪到该内存是否被使用。
上面使用的 _heap_alloc_base函数就是一开始介绍的内存分配函数(根据分配内存的大小选择使用__sbh_alloc_block 还是HeapAlloc)。
继续到 _sbh_alloc_block 函数,其中有一段:

用于将所分配的内存调整为16字节的倍数。
并且,其中调用了一个 _sbh_alloc_new_region()函数和 _sbh_alloc_new_group()函数。
首先看相关的数据定义:
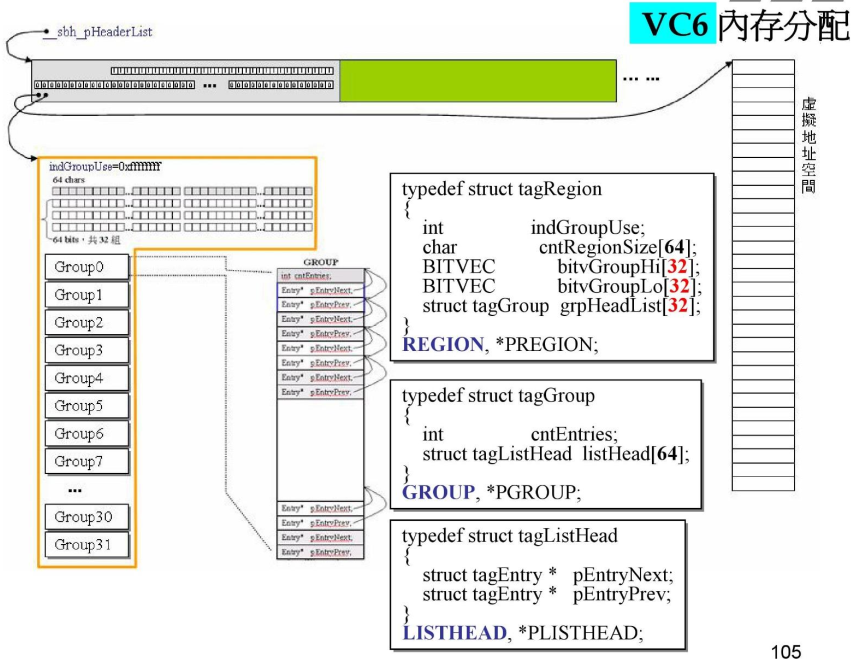
Region管理内存分配细节,其中管理了32个Group,而一个Group中有64个LISTHEAD,可以看出LISTHEAD是双向链表头部,所以一个Group中有64个双向链表。
总体来说,进行分配内存的时候,除了分配出使用的虚拟地址空间(后续从这块内存中切割),还要分配出一个Region来管理那块内存,_sbh_alloc_new_region()就是用来分配出Region的。
每一个Group对应一块虚拟地址空间,虚拟地址空间大小为1024k(1M),所以一个Group管理32k内存。而一个Group中又分成了8个page,一个page对应4k,分配内存时就从这些page中取。
关于虚拟地址空间,其实操作系统并不会立即给它分配内存真正的内存,而是使用时才分配。
page示意:
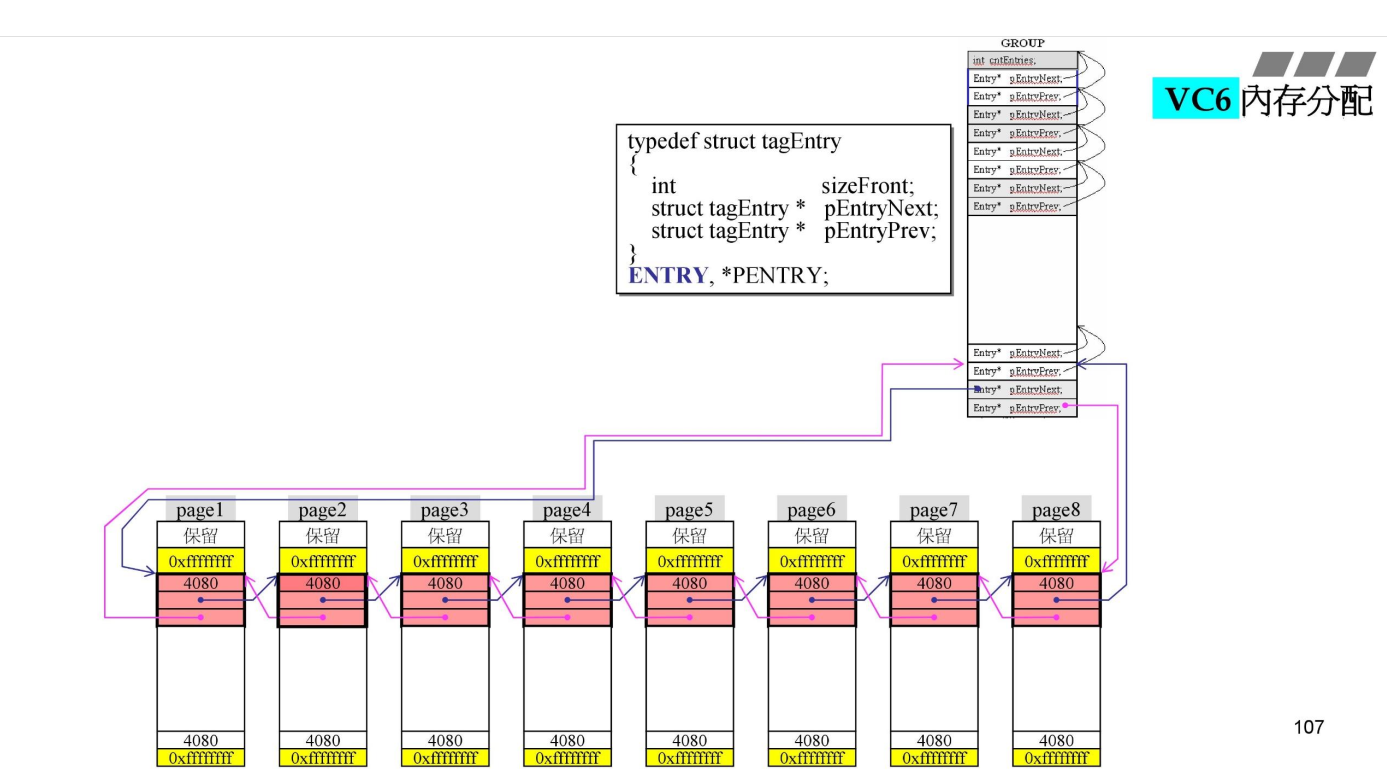
上面的LISTHEAD有两个ENTRY指针,而ENTRY的定义在上图中,ENTRY就是双向链表的节点。
一个Group中有64个链表,每个链表同样负责不同大小的内存分配,以16字节递增。按照计算,最后一个链表应该负责1024字节(1K)大小的内存分配,但是最后一个链表比较特殊,它也负责1k以上大小的内存分配。
初始化完成后,由于每一个page都是4K大小,所以他们都由最后一个链表来管理。
内存分配示意:
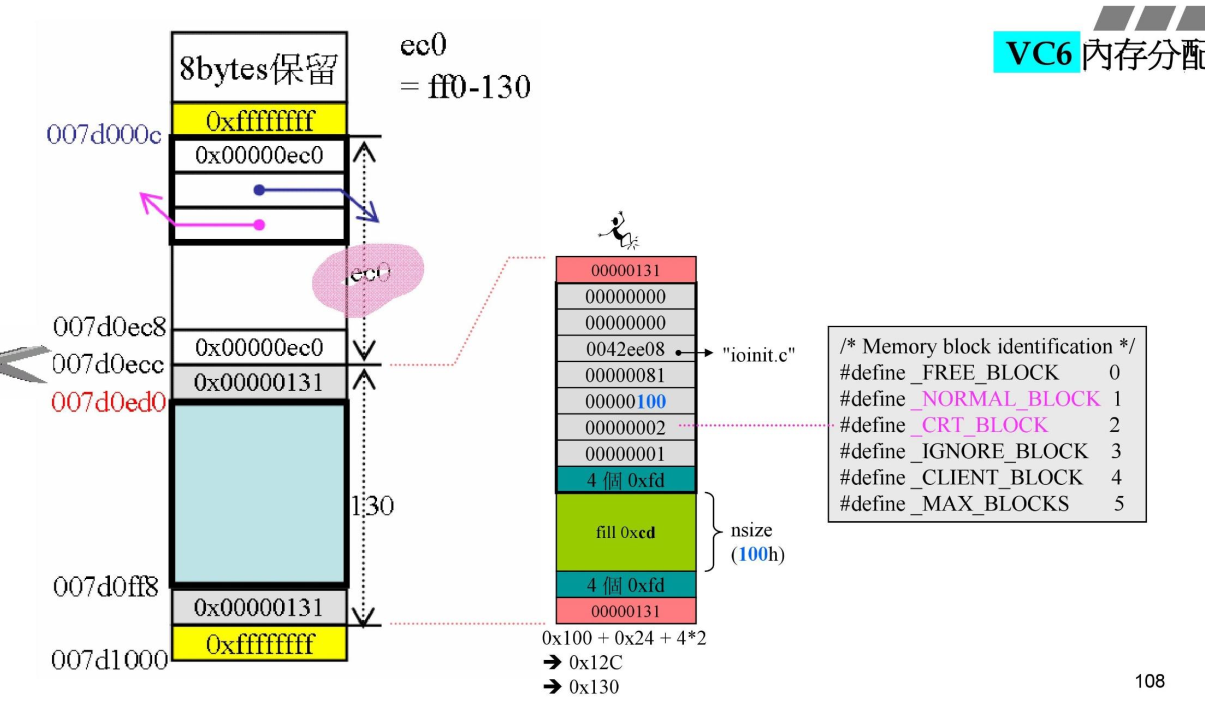
上面是从一个page中为io分配0x130字节的内存分配示意图,从0xff0(4k-16)大小的内存中划出0x130字节,剩余0xec0大小。
当内存释放时,释放的内存会挂到对应的链表上,初始化时所有内存都是由最后一个链表(负责1K以上内存)来管理,此时释放内存,比如释放了0x240字节的内存,这块内存会挂到 0x240 / 0x10 = 0x24 = 36 =#35号链表上(链表编号从0开始),由于每个链表都是双向链表,实现起来比较简单。
当应用程序再次申请内存时,如果申请了比#35号链表所负责的内存更小的内存(35号链表负责 36 * 16 = 576字节的内存),那么会优先从#35号链表分配内存,这么做可以最大化地减少内存碎片,提升内存的使用率。然后如果有剩余的内存,再把它们挂到对应的链表上,就像上一次挂到#35号链表上一样,以此类推。
当不断申请内存,第一个Group剩余的内存不满足需求之后,就开始使用第二个Group的内存。
随着使用内存的次数越来越多,不可避免的会出现许多内存碎片,所以需要将相邻的内存碎片合并成一块,注意每一块内存有两个cookie,上下各一个,当释放一块内存时,会通过cookie判断它的上下两块内存是否在使用中,如果没有使用,它就会和未使用的内存合成一个大区快,然后挂到合适的链表下(这里会通过指针的地址计算它应该落到哪一个Header上,然后通过偏移计算应该落到哪一个Group里,最后才是根据内存的大小计算落到哪个链表)。
在这个内存分配的管理系统中,一个header管理1M内存,然后它又将这块内存切割成8个Group,每个Group管理32K,一个Group中又分了8个page,每个page负责4K,然后用了64个链表来管理这8个page。所以,判断内存是否可以全回收是很困难的,因为经过了很多次内存分配和回收之后,当前的内存可能挂在了很多个不同的链表里面,为了解决这个问题,在每一个header中都维护了一个cntEntries变量,分配内存时它就加一,释放内存时他就减一,如果他的计数是0,就说明这块内存可以全回收了。
在进行全回收时,并不是马上执行的,有一个__sbh_pHeaderDefer指针指向可以回收内存的header,但是它不会马上被回收,当有第二个可回收的header出现时它才会被回收,然后又把Defer指针指向这第二个header。当然,如果在它defer期间又发生了内存分配,就会从这个header中再次分配内存,Defer指针又会被置空。
Loki Allocator
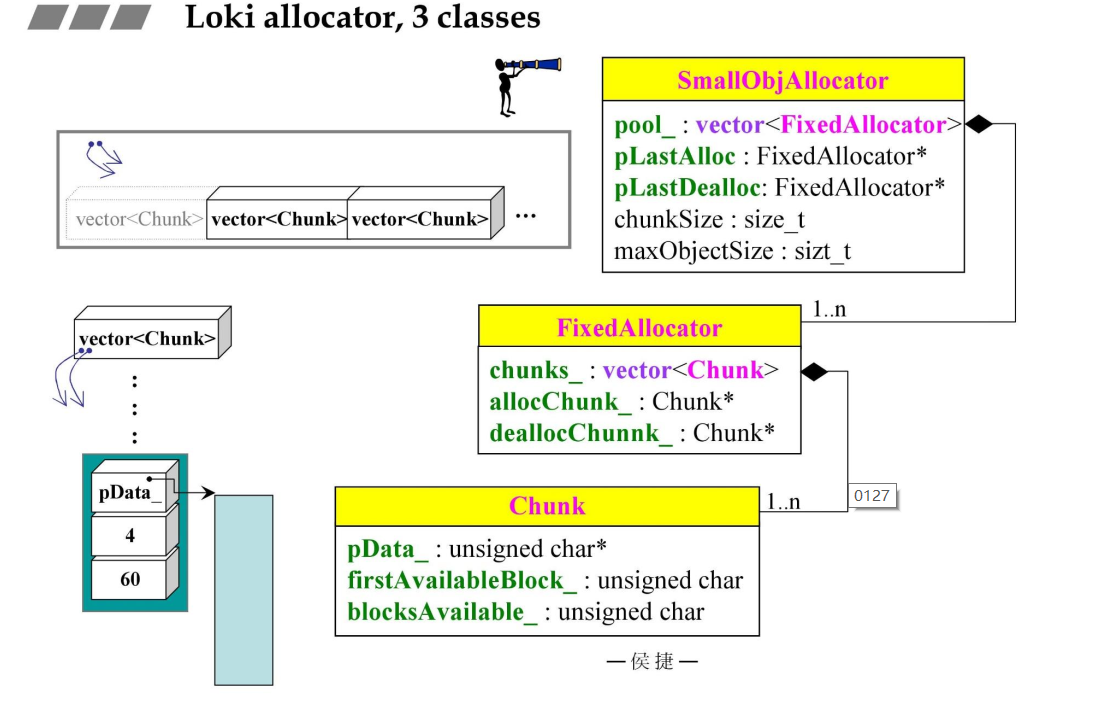
Loki Allocator中重要的3个类,Chunk包含了一个pData指针和两个内存块管理的数据,FixedAllocator包含多个Chunk及这些Chunk的管理数据,SamllObjAllocator又包含了多个FixedAllocator及这些FixedAllocator的管理数据。3个类之间是一个层层包含的关系。
Chunk
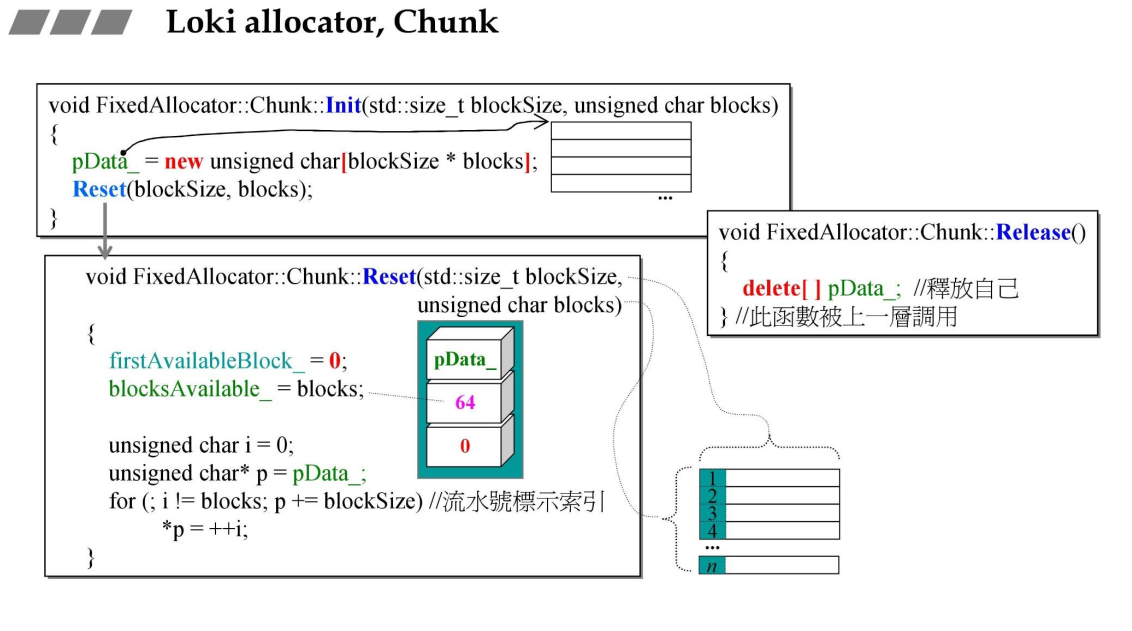
初始化时,传入blockSize和blocks,先使用new分配一大块内存,然后使用reset初始化firstAvailableBlock_ 和blocksAvailable_ , firstAvailableBlock_ 表示第一块可用的block序号,blocksAvailable_ 表示可用的block数量,下面在每个block中借用了一个字节(unsigned char)来保存它的序号,注意序号是从1开始的,也就是说最多有256个区块。Release时释放它所申请的所有内存。
Allocate函数:

分配内存时冲pData_ 偏移到 firstAvailableBlock_ 处取出可用的区块,然后可用区块减一,注意后面吧pResult中的数字赋给了firstAvailableBlock_ ,这表示被分配出去的区块中其实保存的是可分配的下一个区块索引,但之前为每个区块确定序号时明明是顺序分配的,为什么现在又变了?
其实,最开始分配时,每个区块中保存的不是序号,而是指向下一区块的索引。最开始firstAvailableBlock_ 是0,第一次分配必然是从第0块开始的,而第0块保存的索引是1,刚好指向下一块可用的block,后面的以此类推。当进行内存释放时,由于释放的内存并不是按照分配的顺序来的,比如分配了5块内存(0, 1, 2, 3, 4),现在释放第3块内存,firstAvailableBlock_ 必然要等于3,以保证下一次分配内存从这里开始(注意这里从第0块开始计数),然后第3块内存中应该把之前保存的4改为5,因为第4块内存正在使用中,所以随着不断的内存分配和释放,block中的索引并不是顺序的,而是每一块内存中保存了下一块的索引,整个索引数据形成了一个特殊的链表。
理解了这一点之后,再看Deallocate函数:

释放内存时,把firstAvailableBlock_ 保存的下一个可用的block索引写进了toRelease中,然后firstAvailableBlock_ 回退到这次释放的block处,这里通过指针相对于pData_ 的偏移来计算。
FixedAllocator
Allocate函数:
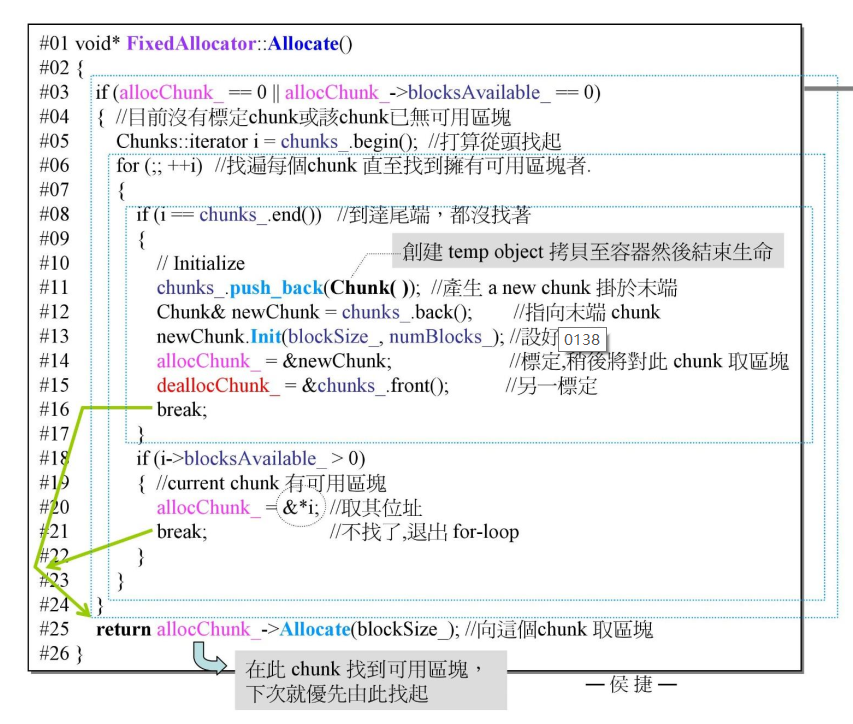
在上面FixedAllocator的介绍中,有allocChunk_ 和deallocChunk_ 两个成员指针,其中allocChunk_ 指向上一个分配内存使用的Chunk,deallocChunk_ 指向上一次内存释放使用的Chunk,这样设计可以比较快速地找到合适的Chunk来进行内存的管理,因为在程序使用中,往往下一次使用的内存会和上一次使用的内存相邻,当然,没有这两个变量也不影响功能,只是在进行内存管理时要遍历一遍chunks_ 来寻找合适的Chunk,更加麻烦。
在进行内存分配时,如果FixedAllocator中的allocChunk_ 已使用完毕,就需要再找一个合适的Chunk来分配内存,遍历所有Chunk,如果还有未使用的Chunk,那就使用它,并使用allocChunk_ 将其记录下来,注意上面的代码中有一行
allocChunk_ = &*i将i解引用再取地址,看起来很奇怪,这是因为i是一个迭代器,不是一个指针,不能将其直接赋给allocChunk_ (迭代器解引用获得它指向的元素)。
如果所有的Chunk都已使用完毕,那就再新建一个Chunk来使用,这里处理完新Chunk后,不但要设置allocChunk_ ,还要设置deallocChunk_ ,这是因为vector新增元素后可能导致内存发生变化,比如移动到另一个地方,指向原来内存的指针都会失效,需要重新设置。
Deallocate函数:

Deallocate函数分为两步,第一步,找到p位于哪个Chunk,并记录到deallocChunk_ ;第二步,释放内存。
VicinityFind函数:

寻找deallocChunk_ 时,会从上一个deallocChunk_ 开始,向chunks两端搜寻,也是考虑到这次释放的内存也许就在上一次释放的内存周围。
DoDeallocate函数:
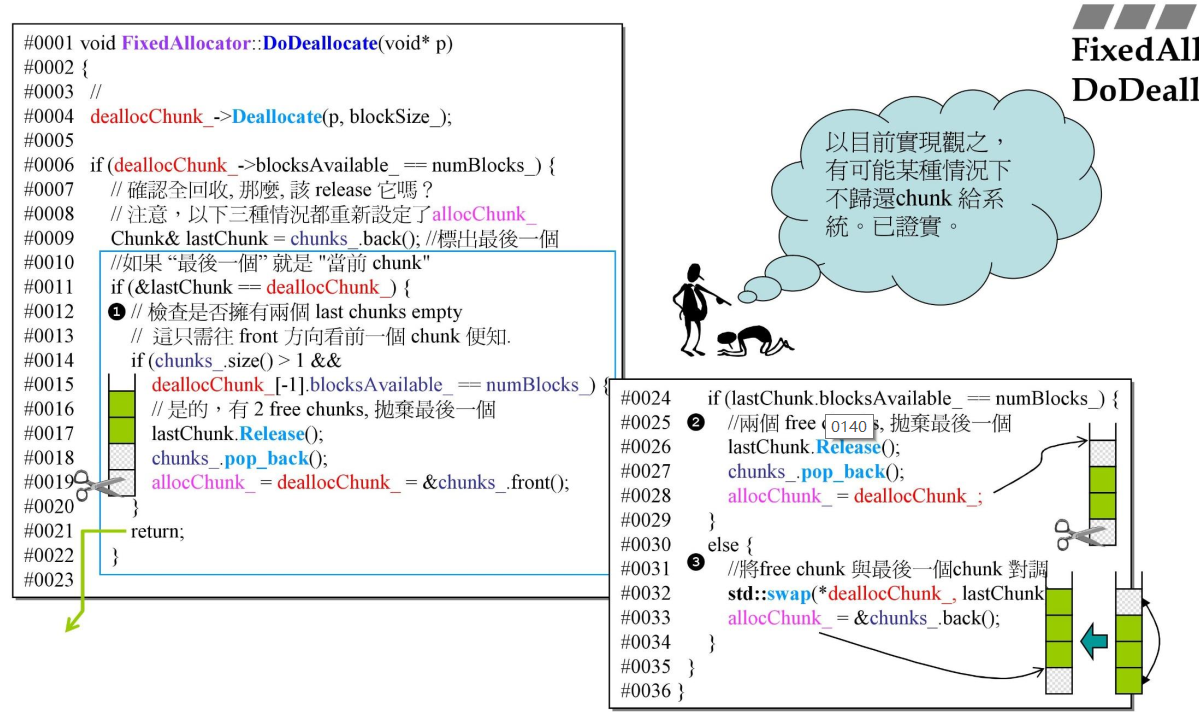
这里只提取了核心部分的实现,调用Chunk的Deallocate函数释放内存后,还需要判断这个Chunk是不是可以全回收。这个全回收也使用了延时回收,当有两个可以全回收的Chunk时,才开始回收第一个。
每次进行全回收时都会把需要回收的Chunk放到chunks的最后,进行全回收判断时有3种情况:
- 当前可以回收的deallocChunk_ 就是最后一个Chunk:先判断前一个Chunk是否也可以全回收,如果可以,就把chunks的最后一个Chunk回收,并重置allocChunk_ 和deallocChunk_ 为第一个Chunk。
- 当前可以回收的deallocChunk_ 不是最后一个Chunk:如果最后一个Chunk可以回收,回收最后一个Chunk,将allocChunk_ 置为deallocChunk_ ,防止指针失效。
- 当前可以回收的deallocChunk_ 不是最后一个Chunk:如果最后一个Chunk还不能回收,交换当前Chunk和最后一个Chunk,将allocChunk_ 置为最后一个Chunk,其实也就是deallocChunk_ 。
这个实现看起来有逻辑漏洞,假设chunks中只有一个Chunk,明显属于第一种情况,但这时它是没有前一个Chunk的,所以不会触发到回收流程,Chunk就无法回收(chunks是否存在只有一个Chunk的情况?)。
按理来说,既然每一次都会先把可以回收的Chunk放到chunks最后,判断一个Chunk的回收时应该只用判断后两种情况,为什么还有第一种情况的判断呢?这是因为把可以回收的Chunk放到chunks最后只在内存释放操作中触发,如果申请内存时加入了新的Chunk,chunks的最后一个元素就又变为新Chunk了。
SamllObjAllocator
这是Loki Allocator中最上层的分配器,其中有多个FixedAllocator,主要是把不同大小的内存管理分配到每一个FixedAllocator上,比如第一个负责20K,第二个负责40K,和之前std::allocator的free_list机制相似,不再赘述。
GUN C++的Allocator

GUN C++的Allocator用于为容器进行内存管理,和上面的std::allocator一样,std::allocator不过为旧版本。
其中主要有一下几个分配器:
- __gun_cxx::new_allocator:直接使用operator new和operator delete。
- __gun_cxx::malloc_allocator:直接使用std::malloc和std::free。
- __gun_cxx::bitmap_allocator:使用了Cache机制,就是最常使用的一次申请一大块内存,然后慢慢切割使用的机制;使用bit_map追踪使用和未使用的内存块。
- __gun_cxx::pool_allocator:就是前面的std::allocator。
- __gun_cxx::mt_allocator:也使用了Cache机制,用于多线程环境下的内存管理。
- __gun_cxx::debug_allocator:本身不做内存管理,是一个wrapper,可以覆盖在任何allocator之上,在申请的内存上加入size信息,保证释放内存时与申请的内存大小相同。
- __gun_cxx::array_allocator:分配固定大小的内存块,使用这个allocator后,大小固定的容器就不需要使用operator new和operator delete了。
new_allocator 和 malloc_allocator 过于简单,这里不再记录。
array_allocator
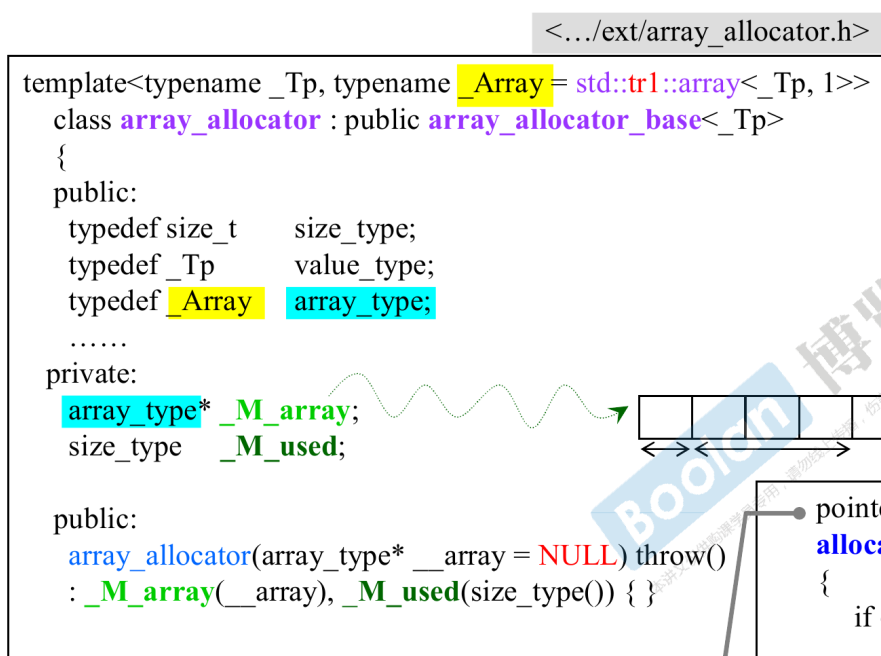
使用array_allocator时需要传入一格std::array类型的参数,这个std::array参数的地址会用于初始化_M_array指针, _M_used用来记录已使用的内存块个数,再看它的allocate函数:

传入需要分配内存的元素个数__n, __ret使用 _M_array头部加上 _M_used来获得可以分配的内存块,这里每个内存块的大小与每个元素的大小是保持一致的,然后更新 _M_used。非常简单易懂,就是预先申请很多个元素的内存,然后需要时一个一个拿出。
array_allocator是没有deallocate函数的(有这个函数声明但什么也不干),也就是说内存只能取,不能回收。
array_allocator的使用示例:

这里声明并初始化了一个array_allocator类型的对象myalloc,它包含了65536 * sizeof(int)大小的内存,然后我们需要保存int类型的数据时,就可以从它那里申请内存。
debug_allocator

debug_allocator初始化时必须传入一个其他分配器,extea计算bytes想当于几个元素,比如extea(int)计算4个字节相当于几个元素。
内存的分配与释放:

分配内存时需要增加_M_extra个元素大小的内存以记录这次分配的元素数量,并且在释放时检查。
bitmap_allocator

可以从这两个函数看出,如果内存分配和释放超过了一个元素,就直接使用了::operatoe new和::operatoe delete,只有申请一个元素时,才会使用它的内存管理策略。回想起来,容器的很多操作都是针对一个元素的,比如插入,删除,这时候bitmap_allocator就起作用了。
bitmap_allocator分配内存时,会分配2的n次方的block,比如64个,然后用一个bitmap记录这些block的使用情况,比如64个block,需要64个bit来记录(使用2个unsigned int),如果block使用了,bit就置1。前面还会使用一个use count(一个unsigned int)来记录已经使用了多少个block。
super block size用来记录总共使用了多少字节,包括bitmap和use count,eg:
peer block size = 8 bytes
super block size = 4 + 2 * 4 + 64 * 8 = 524 bytes
_ _ min_vector_ _用来保存一个super block,它的每一个元素包含了这几个成员:
_M_start指向第一个block;
_M_finsh指向最后一个block;
bitmap_allocator中block是成倍增长的,第一个super block使用完后,再使用第二个super block时,会申请出2倍的block,同理第三个super block会申请4倍的block。显而易见,如果一直不进行内存的全回收,bitmap_allocator使用的内存会越来越大,指数级增长。
super block之间是不会出现混用情况的,分配内存时一定是向同一个super block申请。
当一个super block的内存释放完毕时,它就可以进行全回收,将所有内存都还给操作系统,但是并不是马上归还,可以全回收的super block会被记录到另一个mini_vector,并且从原来的mini_vector删除,当这个free mini_vector中记录了共64个super block时,再有一个可以全回收的super block进来,才会把这65个super block中最大的那个还给操作系统。一旦有一个super block被标记可以全回收,申请新的super block时block就会减半,比如现在申请一个新的super block已经有128个block了,然后有一个super block被标记全回收,那么下一次申请新的super block只有64个block。
已经被记录可以回收的super block会尽量不被使用,比如说一个super block可以全回收了,再需要分配内存时,会优先从其他的super block中取,不会重新使用这个super block,除非其他的super block也使用完了,才会又把这个super block拿出来使用。