在 integrator_intersect_closest对光线和场景进行求交后,如果击中了物体并符合条件,就启动integrator_shade_surface进行物体的着色计算,在这一步才会开始填充render_buffer。
template<uint node_feature_mask = KERNEL_FEATURE_NODE_MASK_SURFACE & ~KERNEL_FEATURE_NODE_RAYTRACE,
DeviceKernel current_kernel = DEVICE_KERNEL_INTEGRATOR_SHADE_SURFACE>
ccl_device_forceinline void integrator_shade_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
const int continue_path_label = integrate_surface<node_feature_mask>(kg, state, render_buffer);
if (continue_path_label == LABEL_NONE) {
integrator_path_terminate(kg, state, current_kernel);
return;
}
...
integrator_shade_surface_next_kernel<current_kernel>(kg, state);
}shade_surface是一个模板函数,第一个模板参数node_feature_mask为KERNEL_FEATURE_NODE_MASK_SURFACE & ~KERNEL_FEATURE_NODE_RAYTRACE,
它的定义为:
#define KERNEL_FEATURE_NODE_MASK_SURFACE \
(KERNEL_FEATURE_NODE_MASK_SURFACE_SHADOW | KERNEL_FEATURE_NODE_RAYTRACE | \
KERNEL_FEATURE_NODE_AOV | KERNEL_FEATURE_NODE_LIGHT_PATH)也就是说它的值为
KERNEL_FEATURE_NODE_MASK_SURFACE_SHADOW | KERNEL_FEATURE_NODE_AOV | KERNEL_FEATURE_NODE_LIGHT_PATH这表示可以进行表面着色的kernel feature?
第二个模板参数为DEVICE_KERNEL_INTEGRATOR_SHADE_SURFACE,标识出当前的kernel。
下面详细拆分每一个步骤:
integrate_surface
这是一个模板函数,模板参数是node_feature_mask,即integrator_intersect_closest的第一个模板参数,它返回continue_path_label,标识此光线是否应该结束。
下面将integrate_surface拆解分析,现在暂时忽略掉一些feature,如,次表面散射,体渲染,path_guiding等。
读取ShaderData
/* Setup shader data. */
ShaderData sd;
integrate_surface_shader_setup(kg, state, &sd);
PROFILING_SHADER(sd.object, sd.shader);ShaderData
ShaderData的定义如下:
typedef struct ccl_align(16) ShaderData
{
/* position */
float3 P;
/* smooth normal for shading */
float3 N;
/* true geometric normal */
float3 Ng;
/* view/incoming direction */
float3 wi;
/* shader id */
int shader;
/* booleans describing shader, see ShaderDataFlag */
int flag;
/* booleans describing object of the shader, see ShaderDataObjectFlag */
int object_flag;
/* primitive id if there is one, ~0 otherwise */
int prim;
/* combined type and curve segment for hair */
int type;
/* object id if there is one, ~0 otherwise */
int object;
/* lamp id if there is one, ~0 otherwise */
int lamp;
/* motion blur sample time */
float time;
/* length of the ray being shaded */
float ray_length;
#ifdef __RAY_DIFFERENTIALS__
/* Radius of differential of P. */
float dP;
/* Radius of differential of wi. */
float dI;
/* differential of u, v */
differential du;
differential dv;
#endif
#ifdef __DPDU__
/* differential of P w.r.t. parametric coordinates. note that dPdu is
* not readily suitable as a tangent for shading on triangles. */
float3 dPdu;
float3 dPdv;
#endif
#ifdef __OBJECT_MOTION__
...
#endif
/* ray start position, only set for backgrounds */
float3 ray_P;
float ray_dP;
#ifdef __OSL__
...
#endif
/* LCG state for closures that require additional random numbers. */
uint lcg_state;
/* Closure data, we store a fixed array of closures */
int num_closure;
int num_closure_left;
/* Closure weights summed directly, so we can evaluate
* emission and shadow transparency with MAX_CLOSURE 0. */
Spectrum closure_emission_background;
Spectrum closure_transparent_extinction;
/* At the end so we can adjust size in ShaderDataTinyStorage. */
struct ShaderClosure closure[MAX_CLOSURE];
}
ShaderData;其中包含了着色计算所需的信息。这些信息贯穿渲染中的整个着色流程,作为context一样的存在。
integrate_surface_shader_setup:
ccl_device_forceinline void integrate_surface_shader_setup(KernelGlobals kg,
ConstIntegratorState state,
ccl_private ShaderData *sd)
{
Intersection isect ccl_optional_struct_init;
integrator_state_read_isect(state, &isect);
Ray ray ccl_optional_struct_init;
integrator_state_read_ray(state, &ray);
shader_setup_from_ray(kg, sd, &ray, &isect);
}在这里,将场景相交信息和光线信息读取到了isect和ray中,然后继续调用shader_setup_from_ray初始化ShaderData,
shader_setup_from_ray函数对ShaderData的初始化分为以下步骤:
读取相交信息
/* Read intersection data into shader globals.
*
* TODO: this is redundant, could potentially remove some of this from
* ShaderData but would need to ensure that it also works for shadow
* shader evaluation. */
sd->u = isect->u;
sd->v = isect->v;
sd->ray_length = isect->t;
sd->type = isect->type;
sd->object = isect->object;
sd->object_flag = kernel_data_fetch(object_flag, sd->object);
sd->prim = isect->prim;
sd->lamp = LAMP_NONE;
sd->flag = 0;这里将isect中的数据放到了sd中,都是一些普通数据。
读取光线信息
/* Read matrices and time. */
sd->time = ray->time;
/* Read ray data into shader globals. */
sd->wi = -ray->D;time用于动画效果,wi是入射光线方向的逆方向(注意这里的光线是指从相机发射的光线,也就是视线方向,相当于渲染方程中的wo),用来进行着色计算。
根据相交的三角形图元进行计算
if (sd->type == PRIMITIVE_TRIANGLE) {
/* static triangle */
float3 Ng = triangle_normal(kg, sd);
sd->shader = kernel_data_fetch(tri_shader, sd->prim);
/* vectors */
sd->P = triangle_point_from_uv(kg, sd, isect->object, isect->prim, isect->u, isect->v);
sd->Ng = Ng;
sd->N = Ng;
/* smooth normal */
if (sd->shader & SHADER_SMOOTH_NORMAL)
sd->N = triangle_smooth_normal(kg, Ng, sd->prim, sd->u, sd->v);
#ifdef __DPDU__
/* dPdu/dPdv */
triangle_dPdudv(kg, sd->prim, &sd->dPdu, &sd->dPdv);
#endif首先是使用triangle_normal计算三角形的法线,计算方式如下:
/* Normal on triangle. */
ccl_device_inline float3 triangle_normal(KernelGlobals kg, ccl_private ShaderData *sd)
{
/* load triangle vertices */
const uint3 tri_vindex = kernel_data_fetch(tri_vindex, sd->prim);
const float3 v0 = kernel_data_fetch(tri_verts, tri_vindex.x);
const float3 v1 = kernel_data_fetch(tri_verts, tri_vindex.y);
const float3 v2 = kernel_data_fetch(tri_verts, tri_vindex.z);
/* return normal */
if (object_negative_scale_applied(sd->object_flag)) {
return normalize(cross(v2 - v0, v1 - v0));
}
else {
return normalize(cross(v1 - v0, v2 - v0));
}
}这里先通过prim取到三角形的v_index,再通过v_index取出3个顶点,三角形的法线等于三个点构成的两个向量的叉乘。object_negative_scale_applied判断三角形是否应用了负向的缩放,比如把一个物体沿x轴放大-2倍,这时三角形的法线就要反过来。
如果没有使用SHADER_SMOOTH_NORMAL特性,那么ShaderData的N(着色计算的法线)和Ng(三角形几何的法线)都是刚刚计算出的法线,如果使用了SHADER_SMOOTH_NORMAL,那么N还需要对计算出的法线进行平滑处理,
triangle_smooth_normal源码:
/* Interpolate smooth vertex normal from vertices */
ccl_device_inline float3
triangle_smooth_normal(KernelGlobals kg, float3 Ng, int prim, float u, float v)
{
/* load triangle vertices */
const uint3 tri_vindex = kernel_data_fetch(tri_vindex, prim);
float3 n0 = kernel_data_fetch(tri_vnormal, tri_vindex.x);
float3 n1 = kernel_data_fetch(tri_vnormal, tri_vindex.y);
float3 n2 = kernel_data_fetch(tri_vnormal, tri_vindex.z);
float3 N = safe_normalize((1.0f - u - v) * n0 + u * n1 + v * n2);
return is_zero(N) ? Ng : N;
}考虑到整个三角形只有一个面法线,为了保证着色平滑,最好对相交点的法线进行更精确的计算,具体的方法就是使用重心坐标uv来对三角形三个顶点的点法线进行插值,得到最终的法线。
计算完法线之后,再通过prim信息(相交的图元索引)取出此物体的shader,它记录物体的使用的shader的第一个节点的位置。后续还会取出shade_flag,sd→flag = kernel_data_fetch(shaders, (sd→shader & SHADER_MASK)).flags,flag记录了shade的特性。
再下一步是通过相交的uv信息(三角形的重心坐标)计算三角形内的精确相交点位,triangle_point_from_uv源码如下:
/**
* Use the barycentric coordinates to get the intersection location
*/
ccl_device_inline float3 triangle_point_from_uv(KernelGlobals kg,
ccl_private ShaderData *sd,
const int isect_object,
const int isect_prim,
const float u,
const float v)
{
const uint3 tri_vindex = kernel_data_fetch(tri_vindex, isect_prim);
const float3 tri_a = kernel_data_fetch(tri_verts, tri_vindex.x),
tri_b = kernel_data_fetch(tri_verts, tri_vindex.y),
tri_c = kernel_data_fetch(tri_verts, tri_vindex.z);
/* This appears to give slightly better precision than interpolating with w = (1 - u - v). */
float3 P = tri_a + u * (tri_b - tri_a) + v * (tri_c - tri_a);
if (!(sd->object_flag & SD_OBJECT_TRANSFORM_APPLIED)) {
const Transform tfm = object_get_transform(kg, sd);
P = transform_point(&tfm, P);
}
return P;
}同样取出三角形的3个顶点,相交点 P = a + u * vec(b - a) + v * vec(c - a),注意相交点的计算是在物体局部空间中进行的,还需要把它转换到世界空间中。
DPDU暂时忽略。
背面测试
/* backfacing test */
bool backfacing = (dot(sd->Ng, sd->wi) < 0.0f);
if (backfacing) {
sd->flag |= SD_BACKFACING;
sd->Ng = -sd->Ng;
sd->N = -sd->N;
...
}通过法线和入射光线夹角的cos值来计算相交点是否为光照背面,注意wi是入射方向的逆方向,所以夹角cos值小于0表示该点位于物体背面,物体背面的点需要将它的法线反过来,同时将SD_BACKFACING记录到shade_flag中。
Surface Shader 计算
读取完ShaderData,下一步对shader进行计算,对应的代码为:
/* Evaluate shader. */
PROFILING_EVENT(PROFILING_SHADE_SURFACE_EVAL);
surface_shader_eval<node_feature_mask>(kg, state, &sd, render_buffer, path_flag);shader计算的函数为surface_shader_eval,它的源码为:
template<uint node_feature_mask, typename ConstIntegratorGenericState>
ccl_device void surface_shader_eval(KernelGlobals kg,
ConstIntegratorGenericState state,
ccl_private ShaderData *ccl_restrict sd,
ccl_global float *ccl_restrict buffer,
uint32_t path_flag,
bool use_caustics_storage = false)
{
/* If path is being terminated, we are tracing a shadow ray or evaluating
* emission, then we don't need to store closures. The emission and shadow
* shader data also do not have a closure array to save GPU memory. */
int max_closures;
if (path_flag & (PATH_RAY_TERMINATE | PATH_RAY_SHADOW | PATH_RAY_EMISSION)) {
max_closures = 0;
}
else {
max_closures = use_caustics_storage ? CAUSTICS_MAX_CLOSURE : kernel_data.max_closures;
}
sd->num_closure = 0;
sd->num_closure_left = max_closures;
#ifdef __OSL__
...
#endif
{
#ifdef __SVM__
svm_eval_nodes<node_feature_mask, SHADER_TYPE_SURFACE>(kg, state, sd, buffer, path_flag);
#else
...
#endif
}
}接下来详细拆解分析此函数。
计算max_closures
这一步计算ShaderGraph中有多少了closure,在上面的代码注释中有说明,当光线路径有PATH_RAY_TERMINATE | PATH_RAY_SHADOW | PATH_RAY_EMISSION 3种标志时,max_closures为0,因为此时它们不需要存储closures。PATH_RAY_TERMINATE意味着此光线路径需要结束,自然不需要储存closures;PATH_RAY_SHADOW表示此光线路径为shadow ray,不进行着色计算,也不需要储存closures;PATH_RAY_EMISSION表示这是一条自发光物体发射的光线(比如光源),它也不需要存储closures(可能是自发光着色计算是不会出现多个closure)。
如果光线路径不在上诉三种情况,max_closures由use_caustics_storage标记决定,这是焦散功能的标志,这里将其看作false,所以max_closures = kernel_data.max_closures。
计算后的max_closures需要储存到ShaderData中,
sd->num_closure = 0;
sd->num_closure_left = max_closures;这里可以看出num_closure和num_closure_left两个属性的含义,num_closure表示此ShaderData中已实际保存的closure数量,num_closure_left表示未保存的closure数量。目前已保存的closure为空,后续会生成这些closure并填充到ShaderData。
计算Shader
Shader中包含了一个ShaderGraph,ShaderGraph中又包含了很多Shader Node。Shader决定了物体的材质,进而决定物体渲染出的外观。
这一步将解析并计算物体的Shader,从上面的代码可以看出,Shader的计算有OSL、SVM和默认3种分支,大多数情况下渲染使用的是SVM,关于SVM,在SVM文章中有详细介绍。
使用SVM计算Shader:
svm_eval_nodes<node_feature_mask, SHADER_TYPE_SURFACE>(kg, state, sd, buffer, path_flag);svm_eval_nodes
这个函数就是计算shader的核心代码,它的源码片段如下:
/* Main Interpreter Loop */
template<uint node_feature_mask, ShaderType type, typename ConstIntegratorGenericState>
ccl_device void svm_eval_nodes(KernelGlobals kg,
ConstIntegratorGenericState state,
ccl_private ShaderData *sd,
ccl_global float *render_buffer,
uint32_t path_flag)
{
float stack[SVM_STACK_SIZE];
Spectrum closure_weight;
int offset = sd->shader & SHADER_MASK;
while (1) {
uint4 node = read_node(kg, &offset);
switch (node.x) {
...
}
}
}这是整个函数的结构,它的主体是一个死循环,不断地遍历Shader中的每一个节点,并对它们进行计算。
在SVM中,每一个Shader节点都会被编译成一个或多个SVM Node,SVM Node计算产生相关的数据会被存到一个stack中,供后续的节点使用,所以这里也定义了一个stack,用来保存这些数据。
closure_weight用于保存closure的计算结果Doubtful ,它的类型为Spectrum,意为光谱,实际是一个float3类型,
#define SPECTRUM_CHANNELS 3
#define SPECTRUM_DATA_TYPE float3
using Spectrum = SPECTRUM_DATA_TYPE;offset取出此shader的偏移地址,sd→shader在根据相交的三角形图元进行计算中初始化,它指示了shader第一个节点的位置。
read_node从场景的所有节点中根据offset读取节点,它的源码:
ccl_device_inline uint4 read_node(KernelGlobals kg, ccl_private int *offset)
{
uint4 node = kernel_data_fetch(svm_nodes, *offset);
(*offset)++;
return node;
}在这里offset会自动增加。
SVM Node的类型一定是放在int4的第一个数据的,所以取出node后根据node.x来判断它的类型。
了解了svm_eval_nodes的运作机制之后,下面是一些计算这些node的例子
SVM Node示例
NODE_VALUE_F
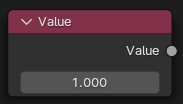
这个节点可以让用户直接使用,假设在某些节点的输入中直接输入了float值(比如BSDF节点的roughness),SVM也会自动生成这个节点。很明显这是一个输出节点,它没有任何输入,所有Shader的第一个节点必然是这种输出节点,即使用户没有使用SVM也会自动生成。
处理它的代码片段:
switch (node.x) {
...
SVM_CASE(NODE_VALUE_F)
svm_node_value_f(kg, sd, stack, node.y, node.z);
break;
...
}svm_node_value_f源码:
ccl_device void svm_node_value_f(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
uint ivalue,
uint out_offset)
{
stack_store_float(stack, out_offset, __uint_as_float(ivalue));
}它的“计算”非常简单,在SVM编译时,将他的具体的输出值保存在node.y处,该值在stack的位置保存在node.z处,这里将值保存至stack的对应的位置,等后续的节点使用即可。这里将ivalue从uint转为了float,他们都是4个字节,转换是安全的。
NODE_CLOSURE_BSDF (CLOSURE_BSDF_DIFFUSE_ID)
既然是Shader计算,最重要的自然是BSDF的节点计算,BSDF节点也是所有节点中最复杂的,这里以一个BSDF节点中最简单的Diffuse BSDF节点为例,主要了解Shader计算的流程。
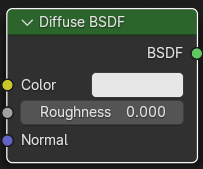
编译Diffuse BSDF
Diffuse BSDF节点的编译函数如下:
void DiffuseBsdfNode::compile(SVMCompiler &compiler)
{
BsdfNode::compile(compiler, input("Roughness"), NULL);
}
void BsdfNode::compile(SVMCompiler &compiler,
ShaderInput *param1,
ShaderInput *param2,
ShaderInput *param3,
ShaderInput *param4)
{
ShaderInput *color_in = input("Color");
ShaderInput *normal_in = input("Normal");
ShaderInput *tangent_in = input("Tangent");
if (color_in->link) {
compiler.add_node(NODE_CLOSURE_WEIGHT, compiler.stack_assign(color_in));
}
else {
compiler.add_node(NODE_CLOSURE_SET_WEIGHT, color);
}
int normal_offset = (normal_in) ? compiler.stack_assign_if_linked(normal_in) : SVM_STACK_INVALID;
int tangent_offset = (tangent_in) ? compiler.stack_assign_if_linked(tangent_in) :
SVM_STACK_INVALID;
int param3_offset = (param3) ? compiler.stack_assign(param3) : SVM_STACK_INVALID;
int param4_offset = (param4) ? compiler.stack_assign(param4) : SVM_STACK_INVALID;
compiler.add_node(
NODE_CLOSURE_BSDF,
compiler.encode_uchar4(closure,
(param1) ? compiler.stack_assign(param1) : SVM_STACK_INVALID,
(param2) ? compiler.stack_assign(param2) : SVM_STACK_INVALID,
compiler.closure_mix_weight_offset()),
__float_as_int((param1) ? get_float(param1->socket_type) : 0.0f),
__float_as_int((param2) ? get_float(param2->socket_type) : 0.0f));
compiler.add_node(normal_offset, tangent_offset, param3_offset, param4_offset);
}Diffuse BSDF主要有4个参数:Roughness,Color,Normal和Tangent。
首先处理颜色参数——生成一个NODE_CLOSURE_WEIGHT或NODE_CLOSURE_SET_WEIGHT节点,并把颜色数据打包进去。
然后处理param1和param2参数,这里param1为Roughness,param2为空,生成一个NODE_CLOSURE_BSDF节点,并将该节点的type(Diffuse BSDF节点的type为CLOSURE_BSDF_DIFFUSE_ID)、param1与param2的位置和值、此Shader的mix_weight_offset(这个几乎不会使用)打包进去。
最后处理Normal、Tangent、param3和param4参数,这里不生成新的节点,仅打包他们的位置数据(说明这四个数据不允许直接填入值,只能连接其他节点的输出,比如Normal必然是不能直接填值的)。
这是生成的3个int4内存示意图,为了方便,假设Color属性是直接输入的颜色值,不与其他节点的输出相连,所以第一个节点是NODE_CLOSURE_SET_WEIGHT。
| int4(1) | int4(2) | int4(3) |
|---|---|---|
| NODE_CLOSURE_SET_WEIGHT | NODE_CLOSURE_BSDF | Normal.offset |
| Color.r | (CLOSURE_BSDF_DIFFUSE_ID, Roughness.offset, null, mix_weight_offset) | Tangent.offset |
| Color.g | Roughness | null |
| Color.b | null | null |
SVM节点处理
知道了Diffuse BSDF生成的节点布局后,再看svm_eval_nodes是如何处理的。
svm_eval_nodes源码片段:
switch (node.x) {
...
SVM_CASE(NODE_CLOSURE_BSDF)
offset = svm_node_closure_bsdf<node_feature_mask, type>(
kg, sd, stack, closure_weight, node, path_flag, offset);
break;
...
SVM_CASE(NODE_CLOSURE_SET_WEIGHT)
svm_node_closure_set_weight(sd, &closure_weight, node.y, node.z, node.w);
break;
...
}首先处理NODE_CLOSURE_SET_WEIGHT,它使用的函数svm_node_closure_set_weight源码为:
ccl_device void svm_node_closure_set_weight(
ccl_private ShaderData *sd, ccl_private Spectrum *closure_weight, uint r, uint g, uint b)
{
*closure_weight = rgb_to_spectrum(
make_float3(__uint_as_float(r), __uint_as_float(g), __uint_as_float(b)));
}它将颜色储存到了closure_weight中,closure_weight是NODE_CLOSURE_BSDF节点的处理函数svm_node_closure_bsdf的一个入参,所以这里相当于将颜色从NODE_CLOSURE_SET_WEIGHT传递到NODE_CLOSURE_BSDF了。
svm_node_closure_bsdf函数比较特殊,
- 它是一个模板函数,有两个模板参数node_feature_mask和type,node_feature_mask记录了shader的一些featue,type记录该Shader的类型,比如SHADER_TYPE_SURFACE。
- 它会返回一个offset,而不借助read_node函数中的offset自增,因为NODE_CLOSURE_BSDF一般不止占用一个int4(比如现在就占用了两个),需要自行计算后续节点的偏移。
读取节点数据1
svm_node_closure_bsdf源码片段:
template<uint node_feature_mask, ShaderType shader_type>
int svm_node_closure_bsdf(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
Spectrum closure_weight,
uint4 node,
uint32_t path_flag,
int offset)
{
uint type, param1_offset, param2_offset;
uint mix_weight_offset;
svm_unpack_node_uchar4(node.y, &type, ¶m1_offset, ¶m2_offset, &mix_weight_offset);
float mix_weight = (stack_valid(mix_weight_offset) ? stack_load_float(stack, mix_weight_offset) : 1.0f);
/* note we read this extra node before weight check, so offset is added */
uint4 data_node = read_node(kg, &offset);
...
}第一步是读取NODE_CLOSURE_BSDF节点关联的数据,node.y中保存的数据为(CLOSURE_BSDF_DIFFUSE_ID, Roughness.offset, null, mix_weight_offset)。mix_weight_offset用于读取mix_weight,它决定了当前BSDF Shader在最终着色计算中的比例(cycles中允许一个材质使用多种BSDF 节点),这里假设只用了Diffuse BSDF,所以mix_weight_offset为空,mix_weight = 1。
read_node读取NODE_CLOSURE_BSDF节点的下一个节点(offset已经自动加1了)。这里保存的是Normal.offset和Tangent.offset。
过滤无需计算的情况
svm_node_closure_bsdf源码片段:
template<uint node_feature_mask, ShaderType shader_type>
int svm_node_closure_bsdf(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
Spectrum closure_weight,
uint4 node,
uint32_t path_flag,
int offset)
{
...
/* Only compute BSDF for surfaces, transparent variable is shared with volume extinction. */
IF_KERNEL_NODES_FEATURE(BSDF)
{
if ((shader_type != SHADER_TYPE_SURFACE) || mix_weight == 0.0f) {
return svm_node_closure_bsdf_skip(kg, offset, type);
}
}
else IF_KERNEL_NODES_FEATURE(EMISSION) {
if (type != CLOSURE_BSDF_PRINCIPLED_ID) {
/* Only principled BSDF can have emission. */
return svm_node_closure_bsdf_skip(kg, offset, type);
}
}
else {
return svm_node_closure_bsdf_skip(kg, offset, type);
}
...
}第二步是过滤掉不需要进行计算的场景,其中使用到了宏IF_KERNEL_NODES_FEATURE,它的定义为:
# define IF_KERNEL_NODES_FEATURE(feature) \
if ((node_feature_mask & (KERNEL_FEATURE_NODE_##feature)) != 0U)所以IF_KERNEL_NODES_FEATURE(BSDF)等价于:
if ((node_feature_mask & (KERNEL_FEATURE_NODE_BSDF)) != 0U)通过模板参数node_feature_mask判断当前节点是否为BSDF节点,同理,IF_KERNEL_NODES_FEATURE(EMISSION)通过模板参数node_feature_mask判断当前节点是否为EMISSION节点。从上面的条件和注释中可以知道svm_node_closure_bsdf只有在两种情况下才会需要计算,
- 该节点为SHADER_TYPE_SURFACE类型的BSDF节点,且mix_weight不为0。
- 该节点为EMISSION类型的节点,且它是一个PRINCIPLED BSDF。
如果确定该节点不需要计算,将调用并返回svm_node_closure_bsdf_skip,它的源码为:
ccl_device_inline int svm_node_closure_bsdf_skip(KernelGlobals kg, int offset, uint type)
{
if (type == CLOSURE_BSDF_PRINCIPLED_ID) {
/* Read all principled BSDF extra data to get the right offset. */
read_node(kg, &offset);
read_node(kg, &offset);
read_node(kg, &offset);
read_node(kg, &offset);
}
return offset;
}用来获取准确的offset。这里就可以看出CLOSURE_BSDF_PRINCIPLED_ID是最特殊的,它的数据比其他的BSDF多占了4个节点。
读取节点数据2
svm_node_closure_bsdf源码片段:
template<uint node_feature_mask, ShaderType shader_type>
int svm_node_closure_bsdf(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
Spectrum closure_weight,
uint4 node,
uint32_t path_flag,
int offset)
{
...
float3 N = stack_valid(data_node.x) ? safe_normalize(stack_load_float3(stack, data_node.x)) : sd->N;
float param1 = (stack_valid(param1_offset)) ? stack_load_float(stack, param1_offset) :
__uint_as_float(node.z);
float param2 = (stack_valid(param2_offset)) ? stack_load_float(stack, param2_offset) :
__uint_as_float(node.w);
...
}继续读取节点的数据,法线N的地址保存在data_node.x,如果该地址为空,就使用三角形图元的法线。后面的param1取出的是Roughness的值,param2未使用,可以忽略。
Setup BSDF
svm_node_closure_bsdf源码片段:
template<uint node_feature_mask, ShaderType shader_type>
int svm_node_closure_bsdf(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
Spectrum closure_weight,
uint4 node,
uint32_t path_flag,
int offset)
{
...
switch (type) {
...
case CLOSURE_BSDF_DIFFUSE_ID: {
Spectrum weight = closure_weight * mix_weight;
ccl_private OrenNayarBsdf *bsdf = (ccl_private OrenNayarBsdf *)bsdf_alloc(
sd, sizeof(OrenNayarBsdf), weight);
...
break;
}
...
}
return offset;
}接下来就是根据不同地BSDF类型进行不同的处理,Diffuse BSDF对应的类型为CLOSURE_BSDF_DIFFUSE_ID。
首先计算weight,weight = closure_weight * mix_weight,其中closure_weight就是basecolor,它是从之前的NODE_CLOSURE_SET_WEIGHT传过来的,mix_weight为BSDF的“权重”。
接下来分配了一个OrenNayarBsdf,先来看下它的定义:
#define SHADER_CLOSURE_BASE \
Spectrum weight; \
ClosureType type; \
float sample_weight; \
float3 N
typedef struct OrenNayarBsdf {
SHADER_CLOSURE_BASE;
float roughness;
float a;
float b;
} OrenNayarBsdf;包含了bsdf计算所需的信息。
Note
OrenNayar指的是Oren-Nayar,一个用于表面反射模型的算法,通过考虑表面微观粗糙度对光的散射效果来更准确地模拟材质的外观。这种模型由迈克尔·奥伦(Michael Oren)和谢弗·乃亚(Shree K. Nayar)在1994年提出。
再看bsdf_alloc函数,它的源码为:
ccl_device_inline ccl_private ShaderClosure *bsdf_alloc(ccl_private ShaderData *sd,
int size,
Spectrum weight)
{
kernel_assert(isfinite_safe(weight));
/* No negative weights allowed. */
weight = max(weight, zero_float3());
const float sample_weight = fabsf(average(weight));
/* Use comparison this way to help dealing with non-finite weight: if the average is not finite
* we will not allocate new closure. */
if (sample_weight >= CLOSURE_WEIGHT_CUTOFF) {
ccl_private ShaderClosure *sc = closure_alloc(sd, size, CLOSURE_NONE_ID, weight);
if (!sc) {
return NULL;
}
sc->sample_weight = sample_weight;
return sc;
}
return NULL;
}这里的计算了sample_weight,它的值为weight三个分量的平均值,从上面的流程可以知道,这里的weight是此BSDF的基础颜色(Base Color),以基础颜色作为BSDF的采样权重,这是在BSDF计算中一种常用的方法,因为基础颜色可以一定程度上反应材质反射或散射光线的能力,这里sample_weight等于基础颜色3个分量的平均值也许并不是十分准确,但依然可以做为采样权重的判断标准,对于其他类型的BSDF,这个sample_weight会有一些调整。
只有sample_weight大于CLOSURE_WEIGHT_CUTOFF(1e-5f),才会进行新的closure分配。需要注意的是,这里调用closure_alloc传入的ClosureType参数是CLOSURE_NONE_ID。
closure_alloc源码:
ccl_device ccl_private ShaderClosure *closure_alloc(ccl_private ShaderData *sd,
int size,
ClosureType type,
Spectrum weight)
{
kernel_assert(size <= sizeof(ShaderClosure));
if (sd->num_closure_left == 0) {
return NULL;
}
ccl_private ShaderClosure *sc = &sd->closure[sd->num_closure];
sc->type = type;
sc->weight = weight;
sd->num_closure++;
sd->num_closure_left--;
return sc;
}所谓的”分配“,其实是在ShaderData的closure数组中取了一个元素出来,并初始化它的type和weight,在这里type其实并未真正初始化,它的值是CLOSURE_NONE_ID。
注意到这里要求分配的size小于等于ShaderClosure的大小,ShaderClosure定义如下:
typedef struct ccl_align(16) ShaderClosure
{
SHADER_CLOSURE_BASE;
/* Extra space for closures to store data, somewhat arbitrary but closures
* assert that their size fits. */
char pad[sizeof(Spectrum) * 2 + sizeof(float) * 4];
}可以看出,除了SHADER_CLOSURE_BASE之外,它至少可以另外包含2个float3和4个float数据,对于OrenNayarBsdf绰绰有余。
分配完成之后,需要记录ShaderData中num_closure和num_closure_left的值,它们在之前计算max_closures阶段被初始化。
BSDF分配完毕之后,再回到svm_node_closure_bsdf函数,
svm_node_closure_bsdf源码片段:
template<uint node_feature_mask, ShaderType shader_type>
int svm_node_closure_bsdf(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private float *stack,
Spectrum closure_weight,
uint4 node,
uint32_t path_flag,
int offset)
{
...
switch (type) {
...
case CLOSURE_BSDF_DIFFUSE_ID: {
...
if (bsdf) {
bsdf->N = N;
float roughness = param1;
if (roughness == 0.0f) {
sd->flag |= bsdf_diffuse_setup((ccl_private DiffuseBsdf *)bsdf);
}
else {
bsdf->roughness = roughness;
sd->flag |= bsdf_oren_nayar_setup(bsdf);
}
}
break;
}
...
}
return offset;
}bsdf分配成功后,初始化它的法线数据,并根据roughness是否为0决定使用DiffuseBsdf还是OrenNayarBsdf,在通常的BSDF模型中diffuse是不考虑roughness的,只有specular才会考虑,OrenNayarBsdf将roughness也考虑进去了。这里假设roughness不为0,需要使用OrenNayarBsdf。
在代码中调用bsdf_diffuse_setup将OrenNayarBsdf强制转为成了DiffuseBsdf,因为DiffuseBsdf中的数据是OrenNayarBsdf的子集,所以这个转换是安全的。
bsdf_oren_nayar_setup源码:
ccl_device int bsdf_oren_nayar_setup(ccl_private OrenNayarBsdf *bsdf)
{
float sigma = bsdf->roughness;
bsdf->type = CLOSURE_BSDF_OREN_NAYAR_ID;
sigma = saturatef(sigma);
float div = 1.0f / (M_PI_F + ((3.0f * M_PI_F - 4.0f) / 6.0f) * sigma);
bsdf->a = 1.0f * div;
bsdf->b = sigma * div;
return SD_BSDF | SD_BSDF_HAS_EVAL;
}针对BSDF的各个属性进行了一些预计算,具体的计算方式为:
并且将bsdf→type赋值为CLOSURE_BSDF_OREN_NAYAR_ID。这个函数最后返回的是SD_BSDF和 SD_BSDF_HAS_EVAL两个标志为,它们会被记录到ShaderData的flag中。这就相当于告诉渲染器,这个ShaderData中有BSDF节点,并且已经进行了预计算。
总结
Surface Shader阶段用于对物体的材质进行处理,物体的材质是通过一个Shader来定义的,它由多个Shader节点组成,所以在进行光照计算前必须对各个节点进行预计算,并确定它最终使用的BSDF模型和对应的参数。
过滤closure
经过上一步的Surface Shader计算之后,ShaderData中已经保存了需要的ShaderClosure,但并不是所有的ShaderClosure都需要计算,可以根据用户的设置进行一些调整,将不需要的closure从着色计算中剔除掉。
integrate_surface源码片段:
template<uint node_feature_mask>
ccl_device int integrate_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
...
/* Filter closures. */
surface_shader_prepare_closures(kg, state, &sd, path_flag);
...
}过滤closure主要使用surface_shader_prepare_closures函数,下面分析它是如何过滤调不需要的closure的。
surface_shader_prepare_closures源码片段:
ccl_device_inline void surface_shader_prepare_closures(KernelGlobals kg,
ConstIntegratorState state,
ccl_private ShaderData *sd,
const uint32_t path_flag)
{
/* Filter out closures. */
if (kernel_data.integrator.filter_closures) {
const int filter_closures = kernel_data.integrator.filter_closures;
if (filter_closures & FILTER_CLOSURE_EMISSION) {
sd->closure_emission_background = zero_spectrum();
}
if (path_flag & PATH_RAY_CAMERA) {
if (filter_closures & FILTER_CLOSURE_DIRECT_LIGHT) {
sd->flag &= ~SD_BSDF_HAS_EVAL;
}
for (int i = 0; i < sd->num_closure; i++) {
ccl_private ShaderClosure *sc = &sd->closure[i];
const bool filter_diffuse = (filter_closures & FILTER_CLOSURE_DIFFUSE);
const bool filter_glossy = (filter_closures & FILTER_CLOSURE_GLOSSY);
const bool filter_transmission = (filter_closures & FILTER_CLOSURE_TRANSMISSION);
const bool filter_glass = filter_glossy && filter_transmission;
if ((CLOSURE_IS_BSDF_DIFFUSE(sc->type) && filter_diffuse) ||
(CLOSURE_IS_BSDF_GLOSSY(sc->type) && filter_glossy) ||
(CLOSURE_IS_BSDF_TRANSMISSION(sc->type) && filter_transmission) ||
(CLOSURE_IS_GLASS(sc->type) && filter_glass))
{
sc->type = CLOSURE_NONE_ID;
sc->sample_weight = 0.0f;
}
else if ((CLOSURE_IS_BSDF_TRANSPARENT(sc->type) &&
(filter_closures & FILTER_CLOSURE_TRANSPARENT))) {
sc->type = CLOSURE_HOLDOUT_ID;
sc->sample_weight = 0.0f;
sd->flag |= SD_HOLDOUT;
}
}
}
}
...
}首先这个功能需要在kernel_data的integrator中保存需要过滤的filter_closures,它是一个bitmap。如果选用过滤CLOSURE_EMISSION,ShaderData中的closure_emission_background会被置0。
下面的过滤只针对PATH_RAY_CAMERA,也就是从相机发出的光线。
如果需要过滤直接光照,ShaderData的flag中的SD_BSDF_HAS_EVAL会被清除,这表示后续不再进行BSDF的计算。
遍历每一个colsure,检查filter_closures中是否过滤DIFFUSE,GLOSSY,TRANSMISSION这些类型的closure,比如上面的OrenNayarBsdf就属于DIFFUSE,如果当前colsure是需要过滤的类型,就将它的type置为CLOSURE_NONE_ID,并将sample_weight置为0。
如果需要过滤的closure类型为TRANSPARENT,就将它的type置为CLOSURE_HOLDOUT_ID,并将sample_weight置为0,然后在ShaderData的flag中保存一个标志位SD_HOLDOUT。
surface_shader_prepare_closures源码片段:
ccl_device_inline void surface_shader_prepare_closures(KernelGlobals kg,
ConstIntegratorState state,
ccl_private ShaderData *sd,
const uint32_t path_flag)
{
...
/* Filter glossy.
*
* Blurring of bsdf after bounces, for rays that have a small likelihood
* of following this particular path (diffuse, rough glossy) */
if (kernel_data.integrator.filter_glossy != FLT_MAX
#ifdef __MNEE__
...
#endif
)
{
...
}
}下面的这个过滤流程主要针对的是焦散的feature,暂时不对它做深入研究。
Note
有没有可能在Shader计算之前做closure的过滤,将filter_closures传递到svm_eval_nodes函数中,在生成bsdf的时候就阻止它。
计算Holdout节点
integrate_surface源码片段:
template<uint node_feature_mask>
ccl_device int integrate_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
...
/* Evaluate holdout. */
if (!integrate_surface_holdout(kg, state, &sd, render_buffer)) {
return LABEL_NONE;
}
...
}Holdout节点是一个Shader节点,它可以让物体变得”透明“,这里的透明指的是渲染出的图像在该物体是透明的,用于实现一些特殊的美术效果,关于它的详细介绍:Blender Holdout节点
由于这个节点比较特殊,所以它不在Surface Shader阶段处理。
Holdout节点实现原理TODO
写入自发光film
integrate_surface源码片段:
template<uint node_feature_mask>
ccl_device int integrate_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
...
/* Write emission. */
if (sd.flag & SD_EMISSION) {
integrate_surface_emission(kg, state, &sd, render_buffer);
}
...
}这一步并不是渲染所必须的,它可以将场景中的自发光物体写入一个”纹理“之中,在后处理阶段就可以使用它来实现一些美术效果。
#TODO
确认光线是否结束
integrate_surface源码片段:
template<uint node_feature_mask>
ccl_device int integrate_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
...
/* Perform path termination. Most paths have already been terminated in
* the intersect_closest kernel, this is just for emission and for dividing
* throughput by the probability at the right moment.
*
* Also ensure we don't do it twice for SSS at both the entry and exit point. */
if (integrate_surface_terminate(state, path_flag)) {
return LABEL_NONE;
}
...
}从代码的注释上来看,大部分光线已经在intersect_closest阶段终止了,这个步骤是为了Emission和让throughput除以probability。并且保证在计算sss时光线进入和脱离物体不会触发两次这个步骤。
integrate_surface_terminate源码:
ccl_device_forceinline bool integrate_surface_terminate(IntegratorState state,
const uint32_t path_flag)
{
const float continuation_probability = (path_flag & PATH_RAY_TERMINATE_ON_NEXT_SURFACE) ?
0.0f :
INTEGRATOR_STATE(
state, path, continuation_probability);
if (continuation_probability == 0.0f) {
return true;
}
else if (continuation_probability != 1.0f) {
INTEGRATOR_STATE_WRITE(state, path, throughput) /= continuation_probability;
}
return false;
}continuation_probability保存在path中,如果光线的path_flag不包含PATH_RAY_TERMINATE_ON_NEXT_SURFACE,就将其取出,否则continuation_probability视为0。
如果continuation_probability为0,表示此光线需要终止,否则更新path中的throughput,将它除以continuation_probability。由于最终throughput的值是要乘到光照计算结果的,所以这里就相当于将最终结果除以了continuation_probability,对应俄罗斯轮盘的校正这个步骤。
PATH_RAY_TERMINATE_ON_NEXT_SURFACE这个标志位是在intersect_closest阶段置入的,它的置入条件是此光线已经在俄罗斯轮盘赌中失败并且此光线击中的物体是自发光物体。
那么这个步骤的意义就很清楚了:
- 此光线本来已经需要停止,但是它击中了一个自发光物体,自发光可能是需要写入film里面的,所以在上一步写入自发光film完成后,在这里终止它。
- 这条光线是正常的光线,在这里将他的throughput除以将它除以continuation_probability。
计算直接光照
光照计算是着色最重要的一步了,在上面的步骤中,光照计算所需的数据已经准备完毕,接下来就可以使用蒙特卡洛方法来计算着色了。
integrate_surface源码片段:
template<uint node_feature_mask>
ccl_device int integrate_surface(KernelGlobals kg,
IntegratorState state,
ccl_global float *ccl_restrict render_buffer)
{
...
/* Load random number state. */
RNGState rng_state;
path_state_rng_load(state, &rng_state);
...
/* Direct light. */
PROFILING_EVENT(PROFILING_SHADE_SURFACE_DIRECT_LIGHT);
integrate_surface_direct_light<node_feature_mask>(kg, state, &sd, &rng_state);
...
}path_state_rng_load读取采样的随机数信息,它将会用于蒙特卡洛积分的随机数采样。
PROFILING_EVENT只在CPU渲染时使用,这里忽略它。
计算直接光照的函数为integrate_surface_direct_light。
在光源上采样
计算直接光照时在光源上采样一个点,将他的辐射率作为渲染方程的输入项,用来计算出出射方向(相机方向)的辐射率。
integrate_surface_direct_light源码片段:
/* Path tracing: sample point on light and evaluate light shader, then
* queue shadow ray to be traced. */
template<uint node_feature_mask>
ccl_device_forceinline void integrate_surface_direct_light(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *sd,
ccl_private const RNGState *rng_state)
{
/* Test if there is a light or BSDF that needs direct light. */
if (!(kernel_data.integrator.use_direct_light && (sd->flag & SD_BSDF_HAS_EVAL))) {
return;
}
/* Sample position on a light. */
LightSample ls ccl_optional_struct_init;
{
const uint32_t path_flag = INTEGRATOR_STATE(state, path, flag);
const uint bounce = INTEGRATOR_STATE(state, path, bounce);
const float3 rand_light = path_state_rng_3D(kg, rng_state, PRNG_LIGHT);
if (!light_sample_from_position(kg,
rng_state,
rand_light,
sd->time,
sd->P,
sd->N,
light_link_receiver_nee(kg, sd),
sd->flag,
bounce,
path_flag,
&ls))
{
return;
}
}
kernel_assert(ls.pdf != 0.0f);
...
} 首先可以看到,只有场景中应用了直接光源效果,并且ShaderData中标记了有BSDF需要计算时(SD_BSDF_HAS_EVAL),光照计算的流程才会继续。
后面对场景中的光源进行采样,这里的采样并不是针对所有光源,而是根据光源的大小、亮度以及它们对当前像素影响的重要性来决定每个光源被采样的概率,不同的光线可能会采样到不同的光源,也会得到不同的计算结果。
这里并不详细研究光源的采样算法,只关心光源采样得到的结果。
#TODO
光源采样的结果保存在LightSample结构体中,它的定义为:
/* Light Sample Result */
typedef struct LightSample {
float3 P; /* position on light, or direction for distant light */
float3 Ng; /* normal on light */
float3 D; /* direction from shading point to light */
float t; /* distance to light (FLT_MAX for distant light) */
float u, v; /* parametric coordinate on primitive */
float pdf; /* pdf for selecting light and point on light */
float pdf_selection; /* pdf for selecting light */
float eval_fac; /* intensity multiplier */
int object; /* object id for triangle/curve lights */
int prim; /* primitive id for triangle/curve lights */
int shader; /* shader id */
int lamp; /* lamp id */
int group; /* lightgroup */
LightType type; /* type of light */
} LightSample;其中的每一个成员都有注释。
计算光照强度
通过采样得到了光源的信息之后,就可以以此来计算它在着色点提供的光照强度,也就是入射光的辐射率。
integrate_surface_direct_light源码片段:
template<uint node_feature_mask>
ccl_device_forceinline void integrate_surface_direct_light(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *sd,
ccl_private const RNGState *rng_state)
{
...
/* Evaluate light shader.
*
* TODO: can we reuse sd memory? In theory we can move this after
* integrate_surface_bounce, evaluate the BSDF, and only then evaluate
* the light shader. This could also move to its own kernel, for
* non-constant light sources. */
ShaderDataCausticsStorage emission_sd_storage;
ccl_private ShaderData *emission_sd = AS_SHADER_DATA(&emission_sd_storage);
Ray ray ccl_optional_struct_init;
BsdfEval bsdf_eval ccl_optional_struct_init;
const bool is_transmission = dot(ls.D, sd->N) < 0.0f;
int mnee_vertex_count = 0;
#ifdef __MNEE__
...
#endif
const Spectrum light_eval = light_sample_shader_eval(kg, state, emission_sd, &ls, sd->time);
if (is_zero(light_eval)) {
return;
}
...
} 这里先定义了一个emission_sd_storage,然后将其转换为ShaderData。ShaderDataCausticsStorage的定义为:
/* ShaderDataCausticsStorage needs the same alignment as ShaderData, or else
* the pointer cast in AS_SHADER_DATA invokes undefined behavior. */
typedef struct ccl_align(16) ShaderDataCausticsStorage
{
char pad[sizeof(ShaderData) - sizeof(ShaderClosure) * (MAX_CLOSURE - CAUSTICS_MAX_CLOSURE)];
}
ShaderDataCausticsStorage;它是一个“空”的结构体,仅用于分配内存空间,它的大小为ShaderData减去MAX_CLOSURE - CAUSTICS_MAX_CLOSURE = 64 - 4 = 60个ShaderClosure的大小,也就是说它是一个特殊的ShaderData,一般的ShaderData可以保存64个ShaderClosure,它只可以保存4个ShaderClosure。
AS_SHADER_DATA的定义为:
#define AS_SHADER_DATA(shader_data_tiny_storage) \
((ccl_private ShaderData *)shader_data_tiny_storage)用来将输入类型的指针转换为ShaderData类型的指针。
所以上面的步骤就是为了定义一个ShaderData类型的指针emission_sd,其中没有任何数据,用来保存计算过程中产生的数据。
后面定义的ray,bsdf_eval也是同样用法。
最关键的计算光照的函数为light_sample_shader_eval,他返回一个Spectrum类型的变量light_eval,这就是光源光照强度的计算结果。
接下来详细分析light_sample_shader_eval的计算流程。
计算constant发光体
light_sample_shader_eval源码片段:
/* Evaluate shader on light. */
ccl_device_noinline_cpu Spectrum
light_sample_shader_eval(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *ccl_restrict emission_sd,
ccl_private LightSample *ccl_restrict ls,
float time)
{
/* setup shading at emitter */
Spectrum eval = zero_spectrum();
if (surface_shader_constant_emission(kg, ls->shader, &eval)) {
if ((ls->prim != PRIM_NONE) && dot(ls->Ng, ls->D) > 0.0f) {
ls->Ng = -ls->Ng;
}
}
else {
...
}light_sample_shader_eval的第一步就是通过surface_shader_constant_emission来判断当前光源是不是constant发光体。
surface_shader_constant_emission源码:
ccl_device bool surface_shader_constant_emission(KernelGlobals kg,
int shader,
ccl_private Spectrum *eval)
{
int shader_index = shader & SHADER_MASK;
int shader_flag = kernel_data_fetch(shaders, shader_index).flags;
if (shader_flag & SD_HAS_CONSTANT_EMISSION) {
const float3 emission_rgb = make_float3(
kernel_data_fetch(shaders, shader_index).constant_emission[0],
kernel_data_fetch(shaders, shader_index).constant_emission[1],
kernel_data_fetch(shaders, shader_index).constant_emission[2]);
*eval = rgb_to_spectrum(emission_rgb);
return true;
}
return false;
}从这里可以看出,是否为constant发光体取决于shader_flag中是否包含SD_HAS_CONSTANT_EMISSION,目前想要有这个标志,需要当前shader中自发光节点的颜色和强度输入都是常数,也就是这两个输入不能是其他节点的输出连接过来的。这样就可以直接从传入的shader中的constant_emission直接读取数据,不需要再经过复杂的节点计算了。
读取出的Spectrum信息保存至eval变量中,并且如果该光源是几何体的话,还要将其法线调整保证ls→Ng与ls→D夹角大于90度(注意法线反转的条件是ls→Ng与ls→D点乘大于0,也就是在它们的夹角小于90度的时候才反转),这是因为ls→D是着色点到光源的向量,对于光源来说,它是一个入向量,它与法线的夹角大于90度时它们位于光源同一侧。
计算背景光
light_sample_shader_eval源码片段:
/* Evaluate shader on light. */
ccl_device_noinline_cpu Spectrum
light_sample_shader_eval(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *ccl_restrict emission_sd,
ccl_private LightSample *ccl_restrict ls,
float time)
{
/* setup shading at emitter */
Spectrum eval = zero_spectrum();
if (surface_shader_constant_emission(kg, ls->shader, &eval)) {
...
}
else {
/* Setup shader data and call surface_shader_eval once, better
* for GPU coherence and compile times. */
PROFILING_INIT_FOR_SHADER(kg, PROFILING_SHADE_LIGHT_SETUP);
if (ls->type == LIGHT_BACKGROUND) {
shader_setup_from_background(kg, emission_sd, ls->P, ls->D, time);
}
else {
...
}
/* No proper path flag, we're evaluating this for all closures. that's
* weak but we'd have to do multiple evaluations otherwise. */
surface_shader_eval<KERNEL_FEATURE_NODE_MASK_SURFACE_LIGHT>(
kg, state, emission_sd, NULL, PATH_RAY_EMISSION);
/* Evaluate closures. */
if (ls->type == LIGHT_BACKGROUND) {
eval = surface_shader_background(emission_sd);
}
else {
...
}
}如果此次采样的光源是背景光的话,调用shader_setup_from_background计算emission_sd。
shader_setup_from_background源码:
/* ShaderData setup from ray into background */
ccl_device_inline void shader_setup_from_background(KernelGlobals kg,
ccl_private ShaderData *ccl_restrict sd,
const float3 ray_P,
const float3 ray_D,
const float ray_time)
{
/* for NDC coordinates */
sd->ray_P = ray_P;
/* vectors */
sd->P = ray_D;
sd->N = -ray_D;
sd->Ng = -ray_D;
sd->wi = -ray_D;
sd->shader = kernel_data.background.surface_shader;
sd->flag = kernel_data_fetch(shaders, (sd->shader & SHADER_MASK)).flags;
sd->object_flag = 0;
sd->time = ray_time;
sd->ray_length = 0.0f;
sd->object = OBJECT_NONE;
sd->lamp = LAMP_NONE;
sd->prim = PRIM_NONE;
sd->u = 0.0f;
sd->v = 0.0f;
#ifdef __DPDU__
/* dPdu/dPdv */
...
#endif
#ifdef __RAY_DIFFERENTIALS__
/* differentials */
...
#endif
}这里将光源的数据填入了ShaderData中,其中,ray_P是在背景计算时才有的,它的值ls→P是光源的位置或方向(对于没有位置的光源而言);sd→P表示shader点的位置,在背景计算中它被初始化成ls→D;其余的N, Ng, wi都初始化成-ls→D。sd→shader直接取了场景中的背景的shader。
再下一步,调用surface_shader_eval计算emission_sd中的shader,surface_shader_eval在Surface Shader 计算中已经介绍过,使用SVM来处理所有shader节点。在处理shader的background时,sd→closure_emission_background将被初始化为背景颜色,并且为sd→flag置上SD_EMISSION标志位。
最后一步,调用surface_shader_background来计算光照强度,surface_shader_background源码:
ccl_device Spectrum surface_shader_background(ccl_private const ShaderData *sd)
{
if (sd->flag & SD_EMISSION) {
return sd->closure_emission_background;
}
else {
return zero_spectrum();
}
}直接返回sd→closure_emission_background,即背景颜色。
所以背景光强度的计算结果就是设置的背景颜色。
计算其他类型的光源
除了上面两种情况,场景中的光源就是使用了节点的自发光物体或者光源,这类光源可以实现更好的光照效果,计算起来也更加复杂。
light_sample_shader_eval源码片段:
/* Evaluate shader on light. */
ccl_device_noinline_cpu Spectrum
light_sample_shader_eval(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *ccl_restrict emission_sd,
ccl_private LightSample *ccl_restrict ls,
float time)
{
/* setup shading at emitter */
Spectrum eval = zero_spectrum();
if (surface_shader_constant_emission(kg, ls->shader, &eval)) {
...
}
else {
/* Setup shader data and call surface_shader_eval once, better
* for GPU coherence and compile times. */
PROFILING_INIT_FOR_SHADER(kg, PROFILING_SHADE_LIGHT_SETUP);
if (ls->type == LIGHT_BACKGROUND) {
...
}
else {
shader_setup_from_sample(kg,
emission_sd,
ls->P,
ls->Ng,
-ls->D,
ls->shader,
ls->object,
ls->prim,
ls->u,
ls->v,
ls->t,
time,
false,
ls->lamp);
ls->Ng = emission_sd->Ng;
}
/* No proper path flag, we're evaluating this for all closures. that's
* weak but we'd have to do multiple evaluations otherwise. */
surface_shader_eval<KERNEL_FEATURE_NODE_MASK_SURFACE_LIGHT>(
kg, state, emission_sd, NULL, PATH_RAY_EMISSION);
/* Evaluate closures. */
if (ls->type == LIGHT_BACKGROUND) {
...
}
else {
eval = surface_shader_emission(emission_sd);
}
}第一步调用shader_setup_from_sample计算emission_sd,shader_setup_from_sample源码:
ccl_device_inline void shader_setup_from_sample(KernelGlobals kg,
ccl_private ShaderData *ccl_restrict sd,
const float3 P,
const float3 Ng,
const float3 I,
int shader,
int object,
int prim,
float u,
float v,
float t,
float time,
bool object_space,
int lamp)
{
/* vectors */
sd->P = P;
sd->N = Ng;
sd->Ng = Ng;
sd->wi = I;
sd->shader = shader;
if (lamp != LAMP_NONE) {
sd->type = PRIMITIVE_LAMP;
}
else if (prim != PRIM_NONE) {
sd->type = PRIMITIVE_TRIANGLE;
}
else {
sd->type = PRIMITIVE_NONE;
}
/* primitive */
sd->object = object;
sd->lamp = LAMP_NONE;
/* Currently no access to bvh prim index for strand sd->prim. */
sd->prim = prim;
sd->u = u;
sd->v = v;
sd->time = time;
sd->ray_length = t;
sd->flag = kernel_data_fetch(shaders, (sd->shader & SHADER_MASK)).flags;
sd->object_flag = 0;
if (sd->object != OBJECT_NONE) {
sd->object_flag |= kernel_data_fetch(object_flag, sd->object);
#ifdef __OBJECT_MOTION__
...
#endif
/* transform into world space */
if (object_space) {
...
}
if (sd->type == PRIMITIVE_TRIANGLE) {
/* smooth normal */
if (sd->shader & SHADER_SMOOTH_NORMAL) {
sd->N = triangle_smooth_normal(kg, Ng, sd->prim, sd->u, sd->v);
if (!(sd->object_flag & SD_OBJECT_TRANSFORM_APPLIED)) {
object_normal_transform_auto(kg, sd, &sd->N);
}
}
#ifdef __DPDU__
...
#endif
}
else {
#ifdef __DPDU__
...
#endif
}
}
else {
if (lamp != LAMP_NONE) {
sd->lamp = lamp;
}
#ifdef __DPDU__
...
#endif
}
/* backfacing test */
if (sd->prim != PRIM_NONE) {
bool backfacing = (dot(sd->Ng, sd->wi) < 0.0f);
if (backfacing) {
sd->flag |= SD_BACKFACING;
sd->Ng = -sd->Ng;
sd->N = -sd->N;
#ifdef __DPDU__
...
#endif
}
}
#ifdef __RAY_DIFFERENTIALS__
...
#endif
}它的功能时将ls中的数据经过必要的处理后填充到emission_sd中。其中sd→wi表示入射光的方向的逆方向,这里初始化为-ls→D。其余数据都是一些常规的初始化,这里忽略DPDU。
第二步与背景光计算相同,调用surface_shader_eval计算shader,不再赘述。它也和背景光一样,将sd→closure_emission_background将被初始化为自发光颜色。
最后调用surface_shader_emission计算光照强度,它的计算过程如下:
ccl_device Spectrum surface_shader_emission(ccl_private const ShaderData *sd)
{
if (sd->flag & SD_EMISSION) {
return emissive_simple_eval(sd->Ng, sd->wi) * sd->closure_emission_background;
}
else {
return zero_spectrum();
}
}
ccl_device Spectrum emissive_simple_eval(const float3 Ng, const float3 wi)
{
float res = emissive_pdf(Ng, wi);
return make_spectrum(res);
}
/* return the probability distribution function in the direction wi,
* given the parameters and the light's surface normal. This MUST match
* the PDF computed by sample(). */
ccl_device float emissive_pdf(const float3 Ng, const float3 wi)
{
float cosNI = fabsf(dot(Ng, wi));
return (cosNI > 0.0f) ? 1.0f : 0.0f;
}首先通过sd→Ng和sd→wi(法线和入射光逆方向)计算自发光的pdf,它的pdf非常简单,如果Ng和wi夹角小于90度,pdf为1,否则pdf为0,也就是只考虑光源面向物体的一侧的光照,然后再将pdf与自发光颜色相乘。
计算最终的光照强度
经过上面3种不同光源的计算,光照数据已经保存在eval中了,但是最后的光照还需要一点处理,
light_sample_shader_eval源码片段:
/* Evaluate shader on light. */
ccl_device_noinline_cpu Spectrum
light_sample_shader_eval(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *ccl_restrict emission_sd,
ccl_private LightSample *ccl_restrict ls,
float time)
{
...
eval *= ls->eval_fac;
if (ls->lamp != LAMP_NONE) {
ccl_global const KernelLight *klight = &kernel_data_fetch(lights, ls->lamp);
eval *= rgb_to_spectrum(
make_float3(klight->strength[0], klight->strength[1], klight->strength[2]));
}
return eval;
}首先,计算出的光照强度需要乘以ls→eval_fac,它在光源采样的时候得到。其次,如果此光源在场景中是一个真正的光源的话(不是自发光的物体),最终的结果还要乘以光源的强度,因为除了自发光节点外,光源本身也是有颜色和亮度设置的。
计算物体的BSDF
在光照强度计算完毕后,下一步就是计算物体的BSDF。
integrate_surface_direct_light源码片段:
template<uint node_feature_mask>
ccl_device_forceinline void integrate_surface_direct_light(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *sd,
ccl_private const RNGState *rng_state)
{
...
ShaderDataCausticsStorage emission_sd_storage;
ccl_private ShaderData *emission_sd = AS_SHADER_DATA(&emission_sd_storage);
Ray ray ccl_optional_struct_init;
BsdfEval bsdf_eval ccl_optional_struct_init;
const bool is_transmission = dot(ls.D, sd->N) < 0.0f;
int mnee_vertex_count = 0;
...
{
...
/* Evaluate BSDF. */
const float bsdf_pdf = surface_shader_bsdf_eval(kg, state, sd, ls.D, &bsdf_eval, ls.shader);
...
}
...
} BSDF的计算产生两个结果,一个是bsdf_eval,一个是bsdf_pdf,bsdf_pdf是当前光线采用的BSDF的pdf,因为一个物体的Shader可能是多个BSDF的结合。bsdf_eval的定义为:
typedef struct BsdfEval {
Spectrum diffuse;
Spectrum glossy;
Spectrum sum;
} BsdfEval;它包含了3项,漫反射,高光和二者相加的结果。
计算BSDF调用surface_shader_bsdf_eval函数,它的源码片段:
float
surface_shader_bsdf_eval(KernelGlobals kg,
IntegratorState state,
ccl_private ShaderData *sd,
const float3 wo,
ccl_private BsdfEval *bsdf_eval,
const uint light_shader_flags)
{
bsdf_eval_init(bsdf_eval, zero_spectrum());
float pdf = _surface_shader_bsdf_eval_mis(
kg, sd, wo, NULL, bsdf_eval, 0.0f, 0.0f, light_shader_flags);
#if defined(__PATH_GUIDING__) && PATH_GUIDING_LEVEL >= 4
...
#endif
return pdf;
}bsdf_eval_init先将bsdf_eval初始化为0,
ccl_device_inline void bsdf_eval_init(ccl_private BsdfEval *eval, Spectrum value)
{
eval->diffuse = zero_spectrum();
eval->glossy = zero_spectrum();
eval->sum = value;
}然后继续调用_surface_shader_bsdf_eval_mis函数进行计算,
_surface_shader_bsdf_eval_mis源码:
ccl_device_inline float _surface_shader_bsdf_eval_mis(KernelGlobals kg,
ccl_private ShaderData *sd,
const float3 wo,
ccl_private const ShaderClosure *skip_sc,
ccl_private BsdfEval *result_eval,
float sum_pdf,
float sum_sample_weight,
const uint light_shader_flags)
{
/* This is the veach one-sample model with balance heuristic,
* some PDF factors drop out when using balance heuristic weighting. */
for (int i = 0; i < sd->num_closure; i++) {
ccl_private const ShaderClosure *sc = &sd->closure[i];
if (sc == skip_sc) {
continue;
}
if (CLOSURE_IS_BSDF_OR_BSSRDF(sc->type)) {
if (CLOSURE_IS_BSDF(sc->type) && !_surface_shader_exclude(sc->type, light_shader_flags)) {
float bsdf_pdf = 0.0f;
Spectrum eval = bsdf_eval(kg, sd, sc, wo, &bsdf_pdf);
if (bsdf_pdf != 0.0f) {
bsdf_eval_accum(result_eval, sc, wo, eval * sc->weight);
sum_pdf += bsdf_pdf * sc->sample_weight;
}
}
sum_sample_weight += sc->sample_weight;
}
}
return (sum_sample_weight > 0.0f) ? sum_pdf / sum_sample_weight : 0.0f;
}这里遍历了shader中所有的closure,然后分别对它们进行计算,只有BSDF和BSSRDF的closure才会被计算,其中,又只有未被排除的BSDF才会进入bsdf_eval计算流程,否则只是将该closure的sample_weight加入到sum_sample_weight中。(有的BSDF是会被排除在计算之外的,该信息保存在光源采样时获得的LightSample.shader中)。
通过上面对sample_weight可知,每一个Closure的sample_weight等于它的Base Color乘以它的混合权重(如果有多个BSDF的话),所以他们的和sum_sample_weight会接近于物体的最终颜色。
bsdf_eval
可以看出这是核心计算bsdf的函数,它返回计算结果eval,并且将pdf填充到bsdf_pdf。
bsdf_eval源码片段:
Spectrum
bsdf_eval(KernelGlobals kg,
ccl_private ShaderData *sd,
ccl_private const ShaderClosure *sc,
const float3 wo,
ccl_private float *pdf)
{
Spectrum eval = zero_spectrum();
*pdf = 0.f;
const float3 Ng = (sd->type & PRIMITIVE_CURVE) ? sc->N : sd->Ng;
switch (sc->type) {
case CLOSURE_BSDF_DIFFUSE_ID:
eval = bsdf_diffuse_eval(sc, sd->wi, wo, pdf);
break;
#if defined(__SVM__) || defined(__OSL__)
case CLOSURE_BSDF_OREN_NAYAR_ID:
eval = bsdf_oren_nayar_eval(sc, sd->wi, wo, pdf);
break;
...
}
// 对结果的一些处理
...
return eval;
}这里就是根据closure具体的类型来计算结果,依然以之前的CLOSURE_BSDF_OREN_NAYAR_ID为例,它的计算函数是bsdf_oren_nayar_eval。
bsdf_oren_nayar_eval源码:
ccl_device Spectrum bsdf_oren_nayar_eval(ccl_private const ShaderClosure *sc,
const float3 wi,
const float3 wo,
ccl_private float *pdf)
{
ccl_private const OrenNayarBsdf *bsdf = (ccl_private const OrenNayarBsdf *)sc;
if (dot(bsdf->N, wo) > 0.0f) {
*pdf = 0.5f * M_1_PI_F;
return bsdf_oren_nayar_get_intensity(sc, bsdf->N, wi, wo);
}
else {
*pdf = 0.0f;
return zero_spectrum();
}
}
ccl_device Spectrum bsdf_oren_nayar_get_intensity(ccl_private const ShaderClosure *sc,
float3 n,
float3 v,
float3 l)
{
ccl_private const OrenNayarBsdf *bsdf = (ccl_private const OrenNayarBsdf *)sc;
float nl = max(dot(n, l), 0.0f);
float nv = max(dot(n, v), 0.0f);
float t = dot(l, v) - nl * nv;
if (t > 0.0f)
t /= max(nl, nv) + FLT_MIN;
float is = nl * (bsdf->a + bsdf->b * t);
return make_spectrum(is);
}Oren Nayar光照模型如下:
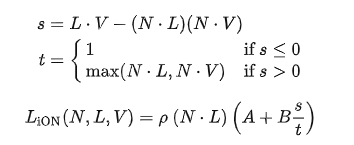
其中的常量A和B已经在Setup BSDF阶段准备数据时已经计算好了,这里暂时没有考虑反照率(也就是baseColor)。