SVM是cycles中使用的shader执行架构,全称为 Shader Virtual Machine,即Shader虚拟机。因为cycles是支持shader graph的,需要有一种方式将各个shader节点及它们的连接方式解析出来,并按照正确的顺序执行,SVM就是为了实现这个功能。
在详细分析SVM之前,先了解cycles的Shader系统中的各个概念。
ShaderNode
ShaderNode是ShaderGraph中的一个Node节点,比如下面的这个Blender中最常用的 BSDF节点,
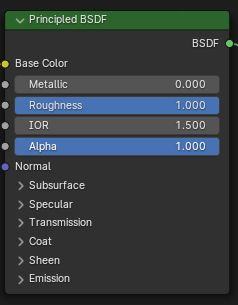
一个node节点包含了多个输入和输出槽,可以连接到其他节点。
ShaderNode类是cycles中所有节点的基类,它继承自Node类(cycles中所有场景中的物体都是Node),包含了每一个node节点都有的属性和方法。
成员变量
ShaderNode类有5个成员:
class ShaderNode : public Node {
...
vector<ShaderInput *> inputs;
vector<ShaderOutput *> outputs;
int id; /* index in graph node array */
ShaderBump bump; /* for bump mapping utility */
ShaderNodeSpecialType special_type; /* special node type */
...
}
inputs和outputs很好理解,表示该节点的输入输出槽,它们的类型ShaderInput和ShaderOutput后面介绍。
id是该node在ShaderGraph中的位置索引。
bump用于bump mapping(凹凸贴图),bump mapping需要重建法线,可能会影响node的计算,ShaderBump定义如下:
/* Bump
*
* For bump mapping, a node may be evaluated multiple times, using different
* samples to reconstruct the normal, this indicates the sample position */
enum ShaderBump { SHADER_BUMP_NONE, SHADER_BUMP_CENTER, SHADER_BUMP_DX, SHADER_BUMP_DY };
表示重建法线时多次采样的位置。
special_type表示该node的特殊类型,只有某些特殊的节点才会用到这个属性,ShaderNodeSpecialType定义:
enum ShaderNodeSpecialType {
SHADER_SPECIAL_TYPE_NONE,
SHADER_SPECIAL_TYPE_PROXY,
SHADER_SPECIAL_TYPE_AUTOCONVERT,
SHADER_SPECIAL_TYPE_GEOMETRY,
SHADER_SPECIAL_TYPE_OSL,
SHADER_SPECIAL_TYPE_IMAGE_SLOT,
SHADER_SPECIAL_TYPE_CLOSURE,
SHADER_SPECIAL_TYPE_COMBINE_CLOSURE,
SHADER_SPECIAL_TYPE_OUTPUT,
SHADER_SPECIAL_TYPE_BUMP,
SHADER_SPECIAL_TYPE_OUTPUT_AOV,
};
构造函数
ShaderNode构造函数如下:
ShaderNode::ShaderNode(const NodeType *type) : Node(type)
{
name = type->name;
id = -1;
bump = SHADER_BUMP_NONE;
special_type = SHADER_SPECIAL_TYPE_NONE;
create_inputs_outputs(type);
}
它接收一个NodeType类型的参数,将name初始化为NodeType的name(name成员是从Node类里继承来的),并将id, bump, special_type初始化成默认值,最后调用create_inputs_outputs(type),根具NodeType初始化输出输出槽。
关于NodeType,只需要知道它有一个name,一个type(NONE或者SHADER),以及输出和输出槽的信息。
create_inputs_outputs定义如下:
void ShaderNode::create_inputs_outputs(const NodeType *type)
{
foreach (const SocketType &socket, type->inputs) {
if (socket.flags & SocketType::LINKABLE) {
inputs.push_back(new ShaderInput(socket, this));
}
}
foreach (const SocketType &socket, type->outputs) {
outputs.push_back(new ShaderOutput(socket, this));
}
}
根据NodeType中的信息初始化inputs和outputs两个属性。
一些重要的成员函数
virtual ShaderNode *clone(ShaderGraph *graph) const = 0;
从ShaderGraph中创建一个当前ShaderNode的拷贝,由具体的节点实现。
virtual void compile(SVMCompiler &compiler) = 0;
定义该节点如何被SVM编译,由具体的节点实现。
/* Get closure ID to which the node compiles into. */
virtual ClosureType get_closure_type()
{
return CLOSURE_NONE_ID;
}
返回该节点的closure ID,这将决定该节点会被编译到哪个closure中,关于closure后面会详细介绍。
ShaderInput
ShaderInput表示ShaderNode的一个输入槽,这个类的定义比较简单,它有以下成员变量:
class ShaderInput{
...
const SocketType &socket_type;
ShaderNode *parent;
ShaderOutput *link;
int stack_offset; /* for SVM compiler */
...
}
socket_type表示该输入槽的数值类型,比如INT,FLOAT,COLOR,VECTOR,也包含了该输入槽的名称等信息。
parent指向该输入槽所属的节点,在ShaderNode中初始化ShaderInput是可以看到传入和this指针。
link指向与该输入槽连接的输出槽,一个输入槽只能与一个输出槽连接。
stack_offset用于SVM编译,后续介绍。
ShaderOutput
ShaderOutput表示ShaderNode的一个输出槽,与ShaderInput相似,它有以下成员变量:
class ShaderInput{
...
const SocketType &socket_type;
ShaderNode *parent;
vector<ShaderInput *> links;
int stack_offset; /* for SVM compiler */
...
}
socket_type, parent, stack_offset三个成员的含义ShaderInput相同。
links指向此输出槽连接的所有输入槽,一个输出槽可以连接多个输入槽,所以它是一个vector。
ShaderGraph
Shader Graph包含了多个Shader Node以及它们的连接关系,并且可以增加或者删除节点及它们的连线。
关于Closure
在详细了解Shader Graph之前,需要先了解Shader系统中Closure的概念。
Closure中文翻译为闭包,在计算机学科中,闭包 = 函数 + 引用环境,即要执行的程序代码加上它引用的各个变量。在Cycles的Shader系统中,如果将每个Shader Node都视为一个函数的话,闭包就等于多个节点连接形成的计算逻辑及它们使用的参数的集合。然而,并不是在Shader Graph随意挑选几个连接好的节点就可以将它们视作一个闭包,在Shader系统中,只用Shader节点及它的前置输入节点的集合才能视作一个闭包,比如下面这个Shader Graph就有一个简单的闭包:
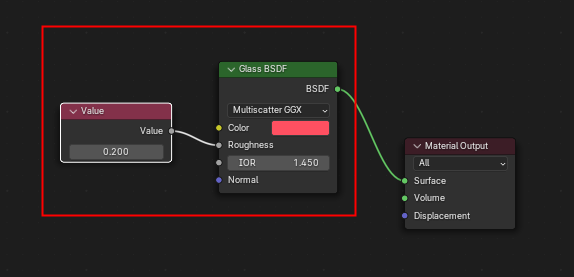
这个闭包包含了Glass BSDF这个Shader节点和它的前置输入节点Value。
这里所说的Shader节点并不是指Shader Node,而是指Shader Node中执行了较复杂的Shader计算的节点,Cycles将这种节点归类到Shader这个分类下面:
在上面的ShaderNode类中有一个get_closure_type函数,它返回ClosureType类型的枚举,并不是所有Shader Node都返回有效的ClosureType,只有上面的Shader才有ClosureType,ClosureType的定义如下:
typedef enum ClosureType {
/* Special type, flags generic node as a non-BSDF. */
CLOSURE_NONE_ID,
CLOSURE_BSDF_ID,
/* Diffuse */
CLOSURE_BSDF_DIFFUSE_ID,
CLOSURE_BSDF_OREN_NAYAR_ID,
CLOSURE_BSDF_DIFFUSE_RAMP_ID,
CLOSURE_BSDF_SHEEN_ID,
CLOSURE_BSDF_DIFFUSE_TOON_ID,
CLOSURE_BSDF_TRANSLUCENT_ID,
/* Glossy */
CLOSURE_BSDF_MICROFACET_GGX_ID,
CLOSURE_BSDF_MICROFACET_BECKMANN_ID,
CLOSURE_BSDF_MICROFACET_MULTI_GGX_ID, /* virtual closure */
CLOSURE_BSDF_ASHIKHMIN_SHIRLEY_ID,
CLOSURE_BSDF_ASHIKHMIN_VELVET_ID,
CLOSURE_BSDF_PHONG_RAMP_ID,
CLOSURE_BSDF_GLOSSY_TOON_ID,
CLOSURE_BSDF_HAIR_REFLECTION_ID,
/* Transmission */
CLOSURE_BSDF_MICROFACET_BECKMANN_REFRACTION_ID,
CLOSURE_BSDF_MICROFACET_GGX_REFRACTION_ID,
CLOSURE_BSDF_HAIR_TRANSMISSION_ID,
/* Glass */
CLOSURE_BSDF_MICROFACET_BECKMANN_GLASS_ID, /* virtual closure */
CLOSURE_BSDF_MICROFACET_GGX_GLASS_ID, /* virtual closure */
CLOSURE_BSDF_MICROFACET_MULTI_GGX_GLASS_ID, /* virtual closure */
CLOSURE_BSDF_HAIR_CHIANG_ID,
CLOSURE_BSDF_HAIR_HUANG_ID,
...
}
并不是每一个Shader节点都对于一个ClosureType,为了便于使用,一个Shader节点可以包含多个ClosureType,比如下面这个Toon BSDF节点,可以需要切换成Diffuse或Glossy模式,分别对应CLOSURE_BSDF_DIFFUSE_TOON_ID和CLOSURE_BSDF_GLOSSY_TOON_ID这两个ClosureType。
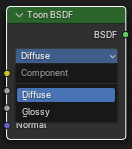
在一个Shader Graph中可以包含多个闭包,它们以不同的权重混合,比如下面这个Shader Graph包含了两个闭包,
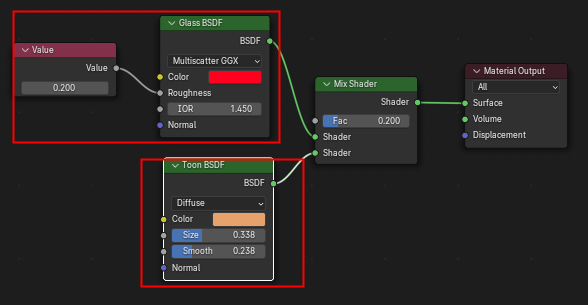
在SVM中,Shader Graph会被打包成一个一个的闭包,并且将它们以二叉树的形式组织起来。
成员变量及初始化
它有以下成员变量,
class ShaderGraph : public NodeOwner {
public:
list<ShaderNode *> nodes;
size_t num_node_ids;
bool finalized;
bool simplified;
string displacement_hash;
...
};
nodes是Shader Graph中所有的Shader Node。
num_node_ids记录Shader Node数量。
finalized标识此Shader Graph是否已经确定,无法再进行修改。
simplified标识此Shader Graph是否已被简化过。
Shader Graph类的初始化,
ShaderGraph::ShaderGraph()
{
finalized = false;
simplified = false;
num_node_ids = 0;
add(create_node<OutputNode>());
}
初始化一个空的Shader Graph时,至少会添加一个OutputNode节点。
重要的成员函数
添加节点
ShaderNode *ShaderGraph::add(ShaderNode *node)
{
assert(!finalized);
simplified = false;
node->id = num_node_ids++;
nodes.push_back(node);
return node;
}
向Shader Graph中添加一个节点时,需要保证 finalized为false,并且要将simplified置为false。从这里也可以看出,Shader Node的id随着node数量的增加而递增,正好对应它在nodes中的索引。
Shader Graph简化
void ShaderGraph::simplify(Scene *scene)
{
if (!simplified) {
expand();
default_inputs(scene->shader_manager->use_osl());
clean(scene);
refine_bump_nodes();
simplified = true;
}
}
针对Shader Graph进行优化,包括了展开节点,读取节点默认值,删除未连接的节点等操作,由于这个步骤对SVM执行的流程影响不大,不再详细展开。
Shader Graph finalize
void ShaderGraph::finalize(Scene *scene, bool do_bump, bool bump_in_object_space)
{
/* before compiling, the shader graph may undergo a number of modifications.
* currently we set default geometry shader inputs, and create automatic bump
* from displacement. a graph can be finalized only once, and should not be
* modified afterwards. */
if (!finalized) {
simplify(scene);
if (do_bump) {
bump_from_displacement(bump_in_object_space);
}
ShaderInput *surface_in = output()->input("Surface");
ShaderInput *volume_in = output()->input("Volume");
/* todo: make this work when surface and volume closures are tangled up */
if (surface_in->link) {
transform_multi_closure(surface_in->link->parent, NULL, false);
}
if (volume_in->link) {
transform_multi_closure(volume_in->link->parent, NULL, true);
}
finalized = true;
}
}
这个函数的描述中说明,每个Shader Graph的finalize只能有一次,并且finalize后就不能再修改这个Shader Graph了,忽略bump map的部分,finalize会自动先执行一次simplify来简化Shader Graph,然后执行transform_multi_closure,这里将transform_multi_closure分成了Surface和Volume两种情况,由于大多数情况下都是使用Surface渲染,这里就只考虑Surface的情况。
transform_multi_closure函数源码片段:
void ShaderGraph::transform_multi_closure(ShaderNode *node, ShaderOutput *weight_out, bool volume)
{
/* for SVM in multi closure mode, this transforms the shader mix/add part of
* the graph into nodes that feed weights into closure nodes. this is too
* avoid building a closure tree and then flattening it, and instead write it
* directly to an array */
if (node->special_type == SHADER_SPECIAL_TYPE_COMBINE_CLOSURE) {
...
}
else {
ShaderInput *weight_in = node->input((volume) ? "VolumeMixWeight" : "SurfaceMixWeight");
/* not a closure node? */
if (!weight_in) {
return;
}
...
}
}
在这个函数的说明里,这个步骤用于在多个closure的情况下将Mix Shader和Add Shader节点转换为权重节点(不同的closure只会以这两个节点来混合)。
从此函数被调用的方式来看,node参数必然是一个closure(Shader类型的节点),在第一个条件判断中,先判断node→special_type == SHADER_SPECIAL_TYPE_COMBINE_CLOSURE,这所有的节点中,只有Mix Shader和Add Shader两个节点的special_type是SHADER_SPECIAL_TYPE_COMBINE_CLOSURE,所以这里是为了判断Shader Graph中是否使用了这两个节点。
大部分情况下Shader Graph中是不会同时使用Mix Shader和Add Shader来混合closure的,所以这里主要看没有这两个节点的情况。
在没有混合closure的情况下,第一步先取出了node的SurfaceMixWeight输入槽(主要考虑Surface渲染的情况)。这个输入槽只有closure才有,但是在Blender中并没有将它暴露出来,可能是内部使用的输入。
void ShaderGraph::transform_multi_closure(ShaderNode *node, ShaderOutput *weight_out, bool volume)
{
if (node->special_type == SHADER_SPECIAL_TYPE_COMBINE_CLOSURE) {
...
}
else {
...
/* not a closure node? */
if (!weight_in) {
return;
}
/* already has a weight connected to it? add weights */
float weight_value = node->get_float(weight_in->socket_type);
if (weight_in->link || weight_value != 0.0f) {
MathNode *math_node = create_node<MathNode>();
add(math_node);
if (weight_in->link) {
connect(weight_in->link, math_node->input("Value1"));
}
else {
math_node->set_value1(weight_value);
}
if (weight_out) {
connect(weight_out, math_node->input("Value2"));
}
else {
math_node->set_value2(1.0f);
}
weight_out = math_node->output("Value");
if (weight_in->link) {
disconnect(weight_in);
}
}
/* connected to closure mix weight */
if (weight_out) {
connect(weight_out, weight_in);
}
else {
node->set(weight_in->socket_type, weight_value + 1.0f);
}
}
}
如果SurfaceMixWeight输入槽有外部连接或者有值的话,下面的操作是加入一个MathNode,MathNode默认情况下运算法则为 output = value1 + value2。然后把MathNode加入到SurfaceMixWeight和它的输入节点之前,MathNode输入为SurfaceMixWeight之前接受的输入和函数的入参weight_out,MathNode的输出作为SurfaceMixWeight的新输入。总体来说就是把SurfaceMixWeight的值和函数入参weight_out相加,得到的结果作为SurfaceMixWeight的新值。
目前这个Shader Graph的finalize操作有点难以理解,首先所有closure的SurfaceMixWeight输入槽都是未开放的,几乎不会有向SurfaceMixWeight连接的节点,其次这个加入MathNode的操作不理解有什么用,既然是想要修改SurfaceMixWeight输入的值,为什么不在这里直接计算,毕竟finalize后这个Shader Graph就不能再改变了。
这样设计原因猜想:SurfaceMixWeight输入并不对用户开放,而是在内部处理Shader Graph时才使用的,这里将SurfaceMixWeight的输入加上了weight_out(如果weight_out传入的时nullptr,那就加上1)是因为SurfaceMixWeight默认输入为0,在之前对SurfaceMixWeight进行操作时并未对它赋值,所以这里才是对它的初始化。如果使用了Mix Shader和Add Shader,这里需要将其替换掉,因为这两个节点在SVM中有其他实现,提供这两个节点只是为了保持与Blender的统一。
在SVM编译时,MixClosureNode没有做任何事。
void MixClosureNode::compile(SVMCompiler & /*compiler*/)
{
/* handled in the SVM compiler */
}
获取closure的数量
int ShaderGraph::get_num_closures()
{
int num_closures = 0;
foreach (ShaderNode *node, nodes) {
ClosureType closure_type = node->get_closure_type();
if (closure_type == CLOSURE_NONE_ID) {
continue;
}
else if (CLOSURE_IS_BSSRDF(closure_type)) {
num_closures += 3;
}
else if (CLOSURE_IS_BSDF_MULTISCATTER(closure_type)) {
num_closures += 2;
}
else if (CLOSURE_IS_PRINCIPLED(closure_type)) {
num_closures += 12;
}
else if (CLOSURE_IS_VOLUME(closure_type)) {
/* TODO(sergey): Verify this is still needed, since we have special minimized volume storage
* for the volume steps. */
num_closures += MAX_VOLUME_STACK_SIZE;
}
else if (closure_type == CLOSURE_BSDF_MICROFACET_BECKMANN_GLASS_ID ||
closure_type == CLOSURE_BSDF_MICROFACET_GGX_GLASS_ID ||
closure_type == CLOSURE_BSDF_HAIR_CHIANG_ID ||
closure_type == CLOSURE_BSDF_HAIR_HUANG_ID)
{
num_closures += 2;
}
else {
++num_closures;
}
}
return num_closures;
}
这个函数统计Shader Graph中closure的数量,关于节点的get_closure_type函数在closure章节中有说明,从这个函数中可以看出,并不是所有类型的closure都是为一个closure,比如BSSRDF的closure视为3个closure,最常用的BSDF_PRINCIPLED视为12个closure。
Shader
Shader直接决定了场景中物体、背景甚至灯光的外观,它是Shader Graph的更高一级封装,每个Shader除了包含一个Shader Graph之外,还包含了关于Shader Graph的一些附加信息,比如是否使用surface shader,这些信息将会影响到Shader的计算方式。
class Shader : public Node {
public:
...
/* shader graph */
ShaderGraph *graph;
...
/* information about shader after compiling */
bool has_surface;
bool has_surface_transparent;
bool has_surface_raytrace;
...
};
Shader中关于Shader Graph的附加信息将在compile后得到。
SVMCompiler
通过前面对Shader系统中各中概念的了解,这里才正式开始接触SVM。
SVMCompiler是SVM的编译器,用于将ShaderGraph编译成便于执行的形式,这个编译并非指计算机程序的编译,只是对ShaderGraph进行进一步的处理,以便于在GPU上也能执行它。
下面是代码中针对SVM的描述注释:
Shder可以看作一些节点的集合,执行Shder就是根据节点计数器顺序地执行这些节点,每个节点关联的数据都是以uint4(4个unsigned int)的形式来储存的,如果一个节点关联的数据超过了这个范围,可以增加节点计数器来适应它(类似将它看作两个节点)。
所有节点的输出都保存在一个stack中,因为节点输出都是color, vector, factor这三种数据,所以栈中的数据都是float类型。stack保存在GPU内部。
shader的执行结果是一个closure,包括它的类型,标签,数据,权重。通过混合closure节点支持对多个closure进行采样,这个逻辑在SVM Compiler中处理。
SVMCompiler用于将Shader编译成多个SVM Node,和Shader Node不同,SVM Node在kernel中定义,并且直接可以在GPU上执行。
内置的数据结构
在SVMCompiler中,定义了下面两个数据结构。
stack
struct Stack {
Stack()
{
memset(users, 0, sizeof(users));
}
Stack(const Stack &other)
{
memcpy(users, other.users, sizeof(users));
}
Stack &operator=(const Stack &other)
{
memcpy(users, other.users, sizeof(users));
return *this;
}
bool empty()
{
for (int i = 0; i < SVM_STACK_SIZE; i++) {
if (users[i]) {
return false;
}
}
return true;
}
int users[SVM_STACK_SIZE];
};
stack虽然叫stack,它本质是一个int的数组,SVM_STACK_SIZE = 255。
SVM中提供了与stack配套的操作函数
int stack_size(SocketType::Type type);
int stack_assign(ShaderOutput *output);
int stack_assign(ShaderInput *input);
int stack_assign_if_linked(ShaderInput *input);
int stack_assign_if_linked(ShaderOutput *output);
int stack_find_offset(int size);
int stack_find_offset(SocketType::Type type);
void stack_clear_offset(SocketType::Type type, int offset);
void stack_link(ShaderInput *input, ShaderOutput *output);
stack_size确认不同Type的数据在stack中占用的元素大小,float和int数据占用1个元素,color, vector, point等占用3个元素。
stack_find_offset(SocketType::Type type)调用stack_find_offset(int size),在svm的active_stack中找出可以存放这种数据类型的位置,比如color类型的数据需要3个元素存放。
int SVMCompiler::stack_find_offset(int size)
{
int offset = -1;
/* find free space in stack & mark as used */
for (int i = 0, num_unused = 0; i < SVM_STACK_SIZE; i++) {
if (active_stack.users[i]) {
num_unused = 0;
}
else {
num_unused++;
}
if (num_unused == size) {
offset = i + 1 - size;
max_stack_use = max(i + 1, max_stack_use);
while (i >= offset) {
active_stack.users[i--] = 1;
}
return offset;
}
}
...
return 0;
}
在active_stack中找到可以存放该类型数据的位置后,会将active_stack中对应的元素置一,并且返回该位置的起始offset。
stack_assign将ShaderOutput或ShaderInput存入stack中,并会根据需要生成SVM Node,存入ShaderInput的方法如下:
int SVMCompiler::stack_assign(ShaderInput *input)
{
/* stack offset assign? */
if (input->stack_offset == SVM_STACK_INVALID) {
if (input->link) {
/* linked to output -> use output offset */
...
}
else {
...
}
return input->stack_offset;
}
首先,存入的ShaderInput的stack_offset必须为SVM_STACK_INVALID,这是ShaderInput的stack_offset默认值,这也就说明一个ShaderInput对象只能存入一次stack。
其次,针对该ShaderInput是否被连接采取不同的存入方法,下面分别讨论这两种情况:
该ShaderInput与一个ShaderOutput连接时:
/* linked to output -> use output offset */
assert(input->link->stack_offset != SVM_STACK_INVALID);
input->stack_offset = input->link->stack_offset;
直接使用它连接的ShaderOutput的stack_offset,这很容易理解,因为ShaderInput的值就是与它连接的ShaderOutput的值。
该ShaderInput未做任何连接:
Node *node = input->parent;
/* not linked to output -> add nodes to load default value */
input->stack_offset = stack_find_offset(input->type());
if (input->type() == SocketType::FLOAT) {
add_node(NODE_VALUE_F,
__float_as_int(node->get_float(input->socket_type)),
input->stack_offset);
}
else if (input->type() == SocketType::INT) {
add_node(NODE_VALUE_F, node->get_int(input->socket_type), input->stack_offset);
}
else if (input->type() == SocketType::VECTOR || input->type() == SocketType::NORMAL ||
input->type() == SocketType::POINT || input->type() == SocketType::COLOR)
{
add_node(NODE_VALUE_V, input->stack_offset);
add_node(NODE_VALUE_V, node->get_float3(input->socket_type));
}
else { /* should not get called for closure */
assert(0);
}
首先调用stack_find_offset在stack中找到该ShaderInput类型的offset,然后根据该ShaderInput类型生成对应的SVM Node,add_node函数用于向compile结果中添加新的SVM Node,比如add_node(NODE_VALUE_F, value1, value2)就是添加了一个NODE_VALUE_F节点,并且它关联的数据是value1和value2,它的实现在后续说明。
这说明假设节点的某一个输入没有连接到其他节点的输出,而是直接输入了一个数时,SVM会为它自动生成Value节点,如果是float数据,就生成一个NODE_VALUE_F,如果时Vector(或Color)数据,就生成两个NODE_VALUE_V。
这种方式保证了Shader Graph编译后的第一个SVM Node一定是NODE_VALUE_XX类型的节点。
将ShaderOutput存入stack的方法如下:
int SVMCompiler::stack_assign(ShaderOutput *output)
{
/* if no stack offset assigned yet, find one */
if (output->stack_offset == SVM_STACK_INVALID) {
output->stack_offset = stack_find_offset(output->type());
}
return output->stack_offset;
}
直接在stack中找到该ShaderOutput类型的offset,因为ShaderOutput的值必然是从SVM Node中计算或读取出来的,只需要为它找到储存的位置即可。
CompilerState
/* Global state of the compiler accessible from the compilation routines. */
struct CompilerState {
explicit CompilerState(ShaderGraph *graph);
/* ** Global state, used by various compilation steps. ** */
/* Set of nodes which were already compiled. */
ShaderNodeSet nodes_done;
/* Set of closures which were already compiled. */
ShaderNodeSet closure_done;
/* Set of nodes used for writing AOVs. */
ShaderNodeSet aov_nodes;
/* ** SVM nodes generation state ** */
/* Flag whether the node with corresponding ID was already compiled or
* not. Array element with index i corresponds to a node with such if.
*/
vector<bool> nodes_done_flag;
/* Node features that can be compiled. */
uint node_feature_mask;
};
从注释上可以看出,CompilerState是complie期间的全局变量,通过它可以访问complie时的状态,主要有nodes_done,保存已编译完毕的节点;closure_done,保存已编译完毕的closure。
成员变量
public
Scene *scene;
ShaderGraph *current_graph;
bool background;
scene:初始化SVMCompile使用的场景。
current_graph:当前compile的ShaderGraph,从下面的current_shader成员中获得。
background:标记当前正在compile的Shader是否为background。
protected
std::atomic_int *svm_node_types_used;
array<int4> current_svm_nodes;
ShaderType current_type;
Shader *current_shader;
Stack active_stack;
int max_stack_use;
uint mix_weight_offset;
uint bump_state_offset;
bool compile_failed;
svm_node_types_used:这是一个bitmap,标记所有使用的SVM Node类型,因为一个场景中的ShaderGraph是并行编译的,所以它的类型是std::atomic_int。
current_svm_nodes:current_graph编译得到的所有SVM Node,每个SVM Node都以一个int4数据保存。
current_type:current_shader的type,默认为SHADER_TYPE_SURFACE。
current_shader:当前编译的Shader,一个场景中可能有多个shader。
active_stack:编译中使用的stack。
max_stack_use:记录使用的最大stack容量。
compile_failed:标记是否compile失败。
compile
compile函数就是SVMCompile最核心的函数,它用于将场景中的Shader编译成多个SVM node,在GPU上就可以按照顺序执行这些SVM node了。
compile函数源码片段:
void SVMCompiler::compile(Shader *shader, array<int4> &svm_nodes, int index, Summary *summary)
{
svm_node_types_used[NODE_SHADER_JUMP] = true;
svm_nodes.push_back_slow(make_int4(NODE_SHADER_JUMP, 0, 0, 0));
/* copy graph for shader with bump mapping */
ShaderNode *output = shader->graph->output();
int start_num_svm_nodes = svm_nodes.size();
...
bool has_bump = (shader->get_displacement_method() != DISPLACE_TRUE) &&
output->input("Surface")->link && output->input("Displacement")->link;
/* finalize */
{
scoped_timer timer((summary != NULL) ? &summary->time_finalize : NULL);
shader->graph->finalize(scene, has_bump, shader->get_displacement_method() == DISPLACE_BOTH);
}
current_shader = shader;
...
}
compile开始时,首先向编译结果svm_nodes中加入一个NODE_SHADER_JUMP节点,这个节关联的数据是(0, 0, 0),加入此节点的作用后续会解释。
然后就是一些变量的初始化和信息提取,不再赘述。Shader Graph的finalize操作在这里完成。
compile函数源码片段:
void SVMCompiler::compile(Shader *shader, array<int4> &svm_nodes, int index, Summary *summary)
{
...
current_shader = shader;
shader->has_surface = false;
shader->has_surface_transparent = false;
shader->has_surface_raytrace = false;
shader->has_surface_bssrdf = false;
shader->has_bump = has_bump;
shader->has_bssrdf_bump = has_bump;
shader->has_volume = false;
shader->has_displacement = false;
shader->has_surface_spatial_varying = false;
shader->has_volume_spatial_varying = false;
shader->has_volume_attribute_dependency = false;
...
}
这里是对shader的初始化,现在很多成员都是false,后面在编译的时候会根据实际情况填充这些数据。
compile函数源码片段:
void SVMCompiler::compile(Shader *shader, array<int4> &svm_nodes, int index, Summary *summary)
{
/* generate bump shader */
...
/* generate surface shader */
{
scoped_timer timer((summary != NULL) ? &summary->time_generate_surface : NULL);
compile_type(shader, shader->graph, SHADER_TYPE_SURFACE);
/* only set jump offset if there's no bump shader, as the bump shader will fall thru to this
* one if it exists */
if (!has_bump) {
svm_nodes[index].y = svm_nodes.size();
}
svm_nodes.append(current_svm_nodes);
}
/* generate volume shader */
...
/* generate displacement shader */
...
/* Fill in summary information. */
...
/* Estimate emission for MIS. */
...
}
这里就是针对不同的shader类型进行具体的编译了,目前只关注surface shader,也就是最常用的表面着色。可以看到,这里是调用了另一个函数compile_type,它根据不同的shader类型执行不同的编译流程。
编译完成后,如果没有使用bump节点(多数情况是未使用的),需要将svm_nodes[index]节点的y参数改为svm_nodes.size()(也就之前编译已生成的SVM Node数量,或者说此次生成的SVM Node的起始位置),通常情况下index的值为0(目前还没有发现不为0的情况),也就是说svm_nodes[index]是第一个SVM Node。上面提到过,在compile开始时,在svm_nodes中会先插入一个NODE_SHADER_JUMP节点,所以第一个SVM Node确定是一个NODE_SHADER_JUMP,这里就是将该NODE_SHADER_JUMP的y参数改为svm_nodes.size()。
最后,将当前shader编译的结果加入到svm_nodes中。
需要注意的是,这里generate shader的流程中,只有bump shader需要根据has_bump来决定是否执行,其余类型的shader都是顺序执行的,也就是说,一个shader可能编译出包含多种shader类型的SVM Nodes,比如同时包含surface shader和volume shader。在volume shader中,svm_nodes.size()保存在NODE_SHADER_JUMP节点的z参数上,在displacement shader中,svm_nodes.size()保存在NODE_SHADER_JUMP节点的w参数上。从这里就可以大概推断出NODE_SHADER_JUMP节点的功能,如果一个shder中包含了多个shader类型,NODE_SHADER_JUMP中的数据保存了每个shader类型编译成的SVM Node的起始位置,后面就可以根据这个位置取出每个shader类型对应的SVM Node。
compile_type
根据不同的shader类型执行不同的编译流程。
compile_type源码片段:
void SVMCompiler::compile_type(Shader *shader, ShaderGraph *graph, ShaderType type)
{
current_type = type;
current_graph = graph;
/* get input in output node */
ShaderNode *output = graph->output();
ShaderInput *clin = NULL;
switch (type) {
case SHADER_TYPE_SURFACE:
clin = output->input("Surface");
break;
case SHADER_TYPE_VOLUME:
...
default:
assert(0);
break;
}
...
}
初始化current_type和current_graph,然后从Output节点中取出与其相连的ShaderInput,通过这个ShaderInput是Output节点的哪个输入就可以判断此shader的类型,比如输入在Surface上就说明此shader类型为 Surface Sahder。
compile_type源码片段:
void SVMCompiler::compile_type(Shader *shader, ShaderGraph *graph, ShaderType type)
{
...
/* clear all compiler state */
memset((void *)&active_stack, 0, sizeof(active_stack));
current_svm_nodes.clear();
foreach (ShaderNode *node, graph->nodes) {
foreach (ShaderInput *input, node->inputs)
input->stack_offset = SVM_STACK_INVALID;
foreach (ShaderOutput *output, node->outputs)
output->stack_offset = SVM_STACK_INVALID;
}
...
}
编译前的初始化,将active_stack和current_svm_nodes清空,并且将所有节点的ShaderInput和ShaderOutput的stack_offset置为SVM_STACK_INVALID。
compile_type源码片段:
void SVMCompiler::compile_type(Shader *shader, ShaderGraph *graph, ShaderType type)
{
...
if (shader->reference_count()) {
CompilerState state(graph);
switch (type) {
case SHADER_TYPE_SURFACE: /* generate surface shader */
find_aov_nodes_and_dependencies(state.aov_nodes, graph, &state);
if (clin->link) {
shader->has_surface = true;
state.node_feature_mask = KERNEL_FEATURE_NODE_MASK_SURFACE;
}
break;
case SHADER_TYPE_VOLUME: /* generate volume shader */
...
default:
break;
}
...
}
只有reference_count不为0的shader才会被编译,也就是确实在场景中使用了的shader。针对Surface Shader,将shader中的has_surface置为true。其他几种shader同理。
find_aov_nodes_and_dependencies是为了处理shader中的aov节点,它用于将shader中的一些计算结果发送至compositing中,可用于一些后处理算法,这里暂时将其忽略。
compile_type源码片段:
void SVMCompiler::compile_type(Shader *shader, ShaderGraph *graph, ShaderType type)
{
...
if (clin->link) {
generate_multi_closure(clin->link->parent, clin->link->parent, &state);
}
/* compile output node */
output->compile(*this);
...
if (type != SHADER_TYPE_BUMP) {
add_node(NODE_END, 0, 0, 0);
}
}
调用generate_multi_closure生成closure,根据Shader生成SVM Nodes。生成完成后,最后处理output节点,这里调用的output→compile就是每个节点自定义的如何将此节点转换为SVM Node的方法,在generate_multi_closure中最终也是使用这个方法来转换各个Shader Node。所有处理完成后,如果此Shader不是SHADER_TYPE_BUMP,就为此Shader加上一个NODE_END节点,标记Shader的结束。
generate_multi_closure
转换Shader中的各个Shader Node,这个转换以每一个closure为单位来执行。
void SVMCompiler::generate_multi_closure(ShaderNode *root_node,
ShaderNode *node,
CompilerState *state)
{
/* only generate once */
if (state->closure_done.find(node) != state->closure_done.end()) {
return;
}
state->closure_done.insert(node);
if (node->special_type == SHADER_SPECIAL_TYPE_COMBINE_CLOSURE) {
...
}
else {
generate_closure_node(node, state);
}
state->nodes_done.insert(node);
state->nodes_done_flag[node->id] = true;
}
除了将各类信息更新至state中以外,最重要的就是根据node的special_type决定不同的流程,前面已经提到过special_type为SHADER_SPECIAL_TYPE_COMBINE_CLOSURE的只有两个节点,就是Mix Shader和Add Shader,它们用于混合两个不同的closure。这里只考虑简单的情况,所以最终调用的是generate_closure_node。
generate_closure_node
生成closure的SVM Nodes的方法。
generate_closure_node源码片段:
void SVMCompiler::generate_closure_node(ShaderNode *node, CompilerState *state)
{
...
/* execute dependencies for closure */
foreach (ShaderInput *in, node->inputs) {
if (in->link != NULL) {
ShaderNodeSet dependencies;
find_dependencies(dependencies, state->nodes_done, in);
generate_svm_nodes(dependencies, state);
}
}
...
}
遍历节点的每一个ShaderInput,寻找与它们相连的node,然后调用generate_svm_nodes生成这些node的SVM Node。generate_closure_node函数传入的node参数必定是一个closure。
find_dependencies用于从一个ShaderInput中寻找它所依赖的所有Shader Node。
generate_closure_node源码片段:
void SVMCompiler::generate_closure_node(ShaderNode *node, CompilerState *state)
{
...
/* closure mix weight */
const char *weight_name = (current_type == SHADER_TYPE_VOLUME) ? "VolumeMixWeight" : "SurfaceMixWeight";
ShaderInput *weight_in = node->input(weight_name);
if (weight_in && (weight_in->link || node->get_float(weight_in->socket_type) != 1.0f)) {
mix_weight_offset = stack_assign(weight_in);
}
else {
mix_weight_offset = SVM_STACK_INVALID;
}
...
}
这里取出该closure的weight并将其保存在stack中,这里只有weight有连接或者不为1的时候会保存。这里mix_weight_offset会记录weight的偏移地址,但是没有看到它有什么用。
generate_closure_node源码片段:
void SVMCompiler::generate_closure_node(ShaderNode *node, CompilerState *state)
{
...
/* compile closure itself */
generate_node(node, state->nodes_done);
mix_weight_offset = SVM_STACK_INVALID;
if (current_type == SHADER_TYPE_SURFACE) {
if (node->has_surface_transparent()) {
current_shader->has_surface_transparent = true;
}
if (node->has_surface_bssrdf()) {
current_shader->has_surface_bssrdf = true;
if (node->has_bssrdf_bump()) {
current_shader->has_bssrdf_bump = true;
}
}
if (node->has_bump()) {
current_shader->has_bump = true;
}
}
}
将closure的依赖节点处理完毕后,调用generate_node处理自身,然后根据该closure的一些信息填充current_shader的各个字段,比如has_surface_bssrdf标记此shader是否含有bssrdf。
generate_svm_nodes
输入一个ShaderNodeSet,将其中的所有nodes转换为SVM Node。
void SVMCompiler::generate_svm_nodes(const ShaderNodeSet &nodes, CompilerState *state)
{
ShaderNodeSet &done = state->nodes_done;
vector<bool> &done_flag = state->nodes_done_flag;
bool nodes_done;
do {
nodes_done = true;
foreach (ShaderNode *node, nodes) {
if (!done_flag[node->id]) {
bool inputs_done = true;
foreach (ShaderInput *input, node->inputs) {
if (input->link && !done_flag[input->link->parent->id]) {
inputs_done = false;
}
}
if (inputs_done) {
generate_node(node, done);
done.insert(node);
done_flag[node->id] = true;
}
else {
nodes_done = false;
}
}
}
} while (!nodes_done);
}
循环遍历这个node集合,每一次都从中挑选出Shader Input都已经处理完毕的节点(即该节点的前置节点已经处理完毕),调用generate_node处理该节点,直到所有节点都处理完毕。这样处理是因为要保证Shader中各个节点的执行顺序,在GPU中,节点都保存在一个数组中,当一个节点执行时,需要保证它的前置节点都已经执行完毕,所以这里将处理一个节点时,必须保证该节点的前置节点已被处理并加入到了svm_nodes数组中。
generate_node
节点转换的最后一步,输入一个Shader Node,输出对应的SVM Node。
void SVMCompiler::generate_node(ShaderNode *node, ShaderNodeSet &done)
{
node->compile(*this);
stack_clear_users(node, done);
stack_clear_temporary(node);
if (current_type == SHADER_TYPE_SURFACE) {
if (node->has_spatial_varying()) {
current_shader->has_surface_spatial_varying = true;
}
if (node->get_feature() & KERNEL_FEATURE_NODE_RAYTRACE) {
current_shader->has_surface_raytrace = true;
}
}
else if (current_type == SHADER_TYPE_VOLUME) {
if (node->has_spatial_varying()) {
current_shader->has_volume_spatial_varying = true;
}
if (node->has_attribute_dependency()) {
current_shader->has_volume_attribute_dependency = true;
}
}
}
最核心的一步是node→compile(*this),调用Shader Node本身的comple方法将自己转换为SVM Node,也就是说每个Shader Node的compile规则是自己定义的。
其中,
stack_clear_users(node, done);
stack_clear_temporary(node);
这两个函数用于优化内存的使用,所有节点的使用的数据都保存在stack中,当一个节点生成数据被使用完毕后,保存这块数据的内存都可以被其他节点复用了,这里就是将数据已被使用完毕的stack内存清空,让其他节点也可以使用这块内存。因为处理这个Shader Node时它的前置节点必然已经被处理完毕了,与其相关的内存使用是可以预测的。
最后就是根据这个节点的信息填充current_shader的信息,比如has_surface_raytrace标记当前shader是否包含raytrace节点。
compile流程总结
SVMCompiler的compile函数本质上是将场景中的所有Shader转换成SVM Node集合,让GPU中也可以进行Shader Graph的逻辑计算。compile过程中,首先要区分该shader的类型,根据不同的类型有不同的编译流程,如果一个shader有多个类型,每种类型的编译流程会顺序执行。确定好类型后,以closure为单位对所有节点进行编译,当编译一个节点时,需要保证它所依赖的所有前置节点都已经编译完毕。编译时调用每个节点自己的compile函数,它定义了当前节点是如何转换成一个SVM Node的。
生成SVM Node时,主要包括以下三种数据:
- SVM Node的类型
- 它所关联的数据,即SVM Node的具体输入数据和输出数据
- 它所关联的数据在stack中的存放地址
这三种数据并不一定同时使用,比如有的节点接受的是别人的输入,它就没有具体的关联数据,只需要保存那些数据在stack中的位置即可,等前面的节点计算完毕,自然可以通过地址取到对应的值,生成SVM Node时,它的类型必然位于数据的第一个位置(每一个SVM Node都是int4类型,将上面三种数据打包到其中)。
Shader Node的compile函数举例
MIX Node
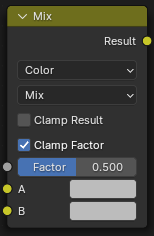
这个节点用于将两种颜色根据Factor混合成一种颜色。
Compile函数:
void MixNode::compile(SVMCompiler &compiler)
{
ShaderInput *fac_in = input("Fac");
ShaderInput *color1_in = input("Color1");
ShaderInput *color2_in = input("Color2");
ShaderOutput *color_out = output("Color");
compiler.add_node(NODE_MIX,
compiler.stack_assign(fac_in),
compiler.stack_assign(color1_in),
compiler.stack_assign(color2_in));
compiler.add_node(NODE_MIX, mix_type, compiler.stack_assign(color_out));
if (use_clamp) {
...
}
}
上面使用compiler.add_node加入了两个SVM Node,两个都是NODE_MIX,第一个关联的数据为fac_in,color1_in,color2_in 三个输入槽,第二个关联mix_type和color_out两个输出槽。从这里可以看出,一个Shader Node并不是对应一个SVM Node。
关于compiler.add_node函数,它的原型如下:
void add_node(ShaderNodeType type, int a = 0, int b = 0, int c = 0);
void add_node(int a = 0, int b = 0, int c = 0, int d = 0);
void add_node(ShaderNodeType type, const float3 &f);
void add_node(const float4 &f);
ShaderNodeType是一个枚举,等同于一个unsigned int。
部分源码:
void SVMCompiler::add_node(int a, int b, int c, int d)
{
current_svm_nodes.push_back_slow(make_int4(a, b, c, d));
}
void SVMCompiler::add_node(ShaderNodeType type, int a, int b, int c)
{
svm_node_types_used[type] = true;
current_svm_nodes.push_back_slow(make_int4(type, a, b, c));
}
add_node函数就是将输入的4个int或float数据打包成一个int4,然后push到current_svm_nodes中。
Brightness/Contrast Node
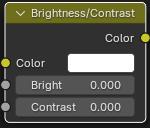
用于调整输入颜色的亮度和对比度。
void BrightContrastNode::compile(SVMCompiler &compiler)
{
ShaderInput *color_in = input("Color");
ShaderInput *bright_in = input("Bright");
ShaderInput *contrast_in = input("Contrast");
ShaderOutput *color_out = output("Color");
compiler.add_node(NODE_BRIGHTCONTRAST,
compiler.stack_assign(color_in),
compiler.stack_assign(color_out),
compiler.encode_uchar4(compiler.stack_assign(bright_in),
compiler.stack_assign(contrast_in)));
}
编译时向current_svm_nodes中加入NODE_BRIGHTCONTRAST,关联的数据为color_in, color_out, bright_in, contrast_in。这里将bright_in,contrast_in打包到了一个int(uchar4)中,因为它们的值都小于255,用一个字节就可以表示。